"The limits of my language are the limits of my world" - Ludwig Wittgenstein
So forewarning this is a highly hypothetical think piece. I struggled with the title and some people might be here thinking it is a practical article.
So I have a soft spot for the idea of AGI. That is human-level intelligence artificial intelligence. I have with my wave neural network idea looking at whether this would work well as an idea for how to develop AGI. So this article is a think piece about formulating a test to develop an AI like this.
Starting Point
My view is the starting point has to be the Turing test. Turing a gay man, mathematician, and technical pioneer whose work in decoding the Enigma engine used by the Nazis in WW2 is an amazing feat of engineering. Then the British government had him chemically castrated for being gay an event believed to lead him to take his own life. One of the greatest minds of our and probably anyone else's lifetime gone.
There is something quite poignant in the Turing test I have always thought. It is simply that a computer program is put on a computer and a normal human on the other, if the user conversing between them cannot tell them apart then surely they are the same. That is to say, and something deeply poignant knowing how the story ended. Given all prejudices being removed if two things are the same then they are the same in the ways that matter.
Though there is an unfortunate shortcoming with the Turing test in that assuming one has many friends willing to run it given the gulf between today's AI and true general intelligence they might not be your friend after subjugating to all the inane conversations with machines who will fail the Turing test. Though I think there is something right in Turing's observation conversation is surely the measure of any other mind why would it not be the measure of an artificial one?
So I have been working on a candidate for AGI. It is a variation on the transformer in that it tries to complete a sentence but unlike many common transformers, it doesn't try to complete the next word in a sentence but predict the next letter. This may seem to add additional complications and it might be because it forces all learning to take place in one network. The more traditional transformers focus on predicting % the chance that the next word will be X or Y word and therefore I think it is unavoidable that you end up with X inputs and X outputs where X is several words that are potentially in the canon.
I also suspect that Transformers probably benefit from some complicated maths to limit down the size and use some gating
I have heard that Google and Microsoft transformers have billions of parameters. I had to double-check that's parameters i.e. inputs not just weights which could be handled by 1000 by 1000 matrix. I don't think I could fit a model on my laptop's memory, I think I could fit a 1000 by 1000 neural network in memory with a terabyte of ram but then how will I watch Netflix?
So I need something smaller than a billion parameters and then to construct a test of a Neural Network that if passed or saw improvement on the test we would conclude it was an improvement towards generalized intelligence in the algorithm. I think you could call it a Bayesian Turing test as the concept takes a bit from Bayes theory on evidence, and Turing insight into AI.
There is a problem with the Turing test that is quite lethal in that it cannot be automated. Therefore a host of algorithm types like genetic algorithms are meant to optimise the hyperparameters and automatically bootstrap the performance up. Therefore this is a thought piece on that sort of heuristic one that identifies something that might represent generalised intelligence to then select for it.
So that's my thoughts.
How I Think About Reinforcement Learning versus General Intelligence
I think it is worth exploring what I mean as a difference between reinforcement learning in which a machine is taught when receiving a set of inputs do Y can be thought as very analogous to the way we teach animals. A dog might be thought to respond in this manner that upon receiving the right command it sits and upon doing the task it is rewarded (or punished if it did the incorrect action) and in doing so it is reinforced into a set of behaviours so upon receiving the command (the input) it does the task.
General intelligence would mean having a variety of models about the world which are all updated and it is from the mix of the models that a guess of the right decision is made. Think about it when a person has a conversation it is probably the only time in their life that they might have that conversation and so could not have had that learning reinforced but have navigated that conversation from lots of generalized rules and past experiences that together add up to an ability to do a thing called having a conversation.
Is this possible in a machine? Well, I don't know but the Microsoft and Google transformers would seem to testify that these machines can manage something similar and if you think that a computer vision neural network could see a boat in a picture and decide it is a boat from that even though it doesn't look like any boat in its training set then that would appear a good indication that something has been learned that appears to be a generalised set of rules.
This is the view taken by James McClelland, David E Rumelhart and the PDP research group in their book Parallel Distributed processing. Where they thought the benefit of the human brain is that all parts of the brain are processing at once and many of its unique features might be related to its massive parallelisation. This is like if we said we would make the brain of a computer but every cell was represented by a highly miniaturised individual processor. I think this might be true but I am unconvinced that it is necessarily true and that we could not find some tell tale signs of general intelligence and work back from that.
That is what I think is needed we need to find the hint of generalised intelligence. If you think of it like this we don't build machines like people; If we did we would have to run a machine for 16-30 years put it through school, college, and a university degree (and probably ladle it with debt) before we ought to be able to start asking it to say "hello world". Therefore we need to detect a machine's ability to think like us before we might be able to make a machine that thinks like us, especially if any of the indicators of potential intelligence are weak or faint.
Therefore the first thing to consider is that maybe we could need machines built differently from normal neural networks. Maybe we currently don't have the technology. At the minimum, I think the standard neural network doesn't demonstrate anything to do with memory and so something with a memory like Google Long Term Short Term Neural Network or something like what I built seems to be a prerequisite. If an AI cannot remember what it is doing moment to moment it seems a major flaw, ideally if this is baked in and scales with the network then eventually at some point build a big enough AI then by sheer processing power it should perform as good or better as a person.
How to run the test
I think Turing was right it is the absence of bias that is the only method by which we might detect intelligence. I think there is a lapse here though which Turing didn't address. If an AI is presented as a perfectly normal 100 IQ test person then we will probably all easily identify it as an "intelligence".
Research on intelligence or IQ in humans is a politically charged debate, made practically harder by any google search on the subject generating lots of google ads offering to sell you an IQ test (probably to make you feel happier about your intelligence, insecurity is uncorrelated with intelligence don't you know).
Though I think IQ gives an insight to maybe the approach to AGI i.e. a continuous value and focus on the low end of the spectrum for developing generalized intelligence and working up the value chain.
The other thing that I think will be required is that it ought to deal with language and I think have to copy the idea from transformers in that an AI should predict the next value in a sequence but focused on letters and not words. The reason for this is that if you didn't it would largely only resemble the Transformers used by google or Microsoft and it wouldn't allow detection of generalised knowledge. The reason is that when a machine got a word correct it naturally and had to pick a word and, obviously by the nature of learning it ought to pick a better word each time overtraining.
You could not choose to say only let a given AI read a single book once and then test it on guessing the next word and conclude it was generalised knowledge across multiple domains. If an AI got a whole word right through using the base level of letters it is A) Atomic and cannot be rendered in any finer detail B) statistically significant as with 61 values with letters, numbers, and grammar that means getting an X letter word correct represents 1/(61**X) likelihood; if you combine that with the potential chance that the machine would do that at the right time matching the details in the book it is reading and trying to predict the next letter then it would be 1/number of words in canon.
This is essentially a Bayesian approach to a Turing test where we consider the AI against the baseline of comparison against random number generation.
PSEUDOCODE:
print("likelihood of event")
print(count of word/count of all words)
print("likelihood of AI saying this randomly")
print(1/(61**len(word)))
print("Times this happened")
print(No times AI said a word while word was next value in book)
print("likelihood this could happen")
print(str(((count of time word in book/count of all words)*(1/(61**len(word))))))
print("likelihood this could happen in this book")
likelihood this could happen in this book * (number of times word exists / times AI said the word)
This was my initial attempt and would allow identifying of unique events that might represent intelligence. My alternative view is to use Shannon's view of information theory - Wikipedia. A totalised score for a given AI would be for each word dividing 1 by the likelihood this could happen in this book which would take the logarithm of this value and total it. This total would give a heuristic score for a given neural network that the higher value would very likely represent an increase in generalised intelligence.
This would I hope represents a better option than calculating a value purely from information theory as doing so would ignore that an AI's likelihood of saying a given word at a point of prompting is itself a likely indicator of intelligence as well as the rarity of the word in the corpus being studied. This heuristic includes all these values and should be finer tuned, i.e. an AI that developed the ability to identify a name as the subject of current sentence despite not being continuously reinforced would represent a more miraculous increase in intelligence and capability as it represents the application of multiple generalised rules over reinforcement learning of a single rule.
Such a test obeys Bayesian inductive thinking, Shannon's information theory, and remains true to the Turing test itself.
Practical Elements of The Test
The network reads a book, to be honest, I am uncertain if it should be allowed to train twice on any book. The aim here would be to predict the next letter in the book and it should resemble a voice as much as possible (but I don't think this is statistically required).
The test ought to be fair because of the following reasons
-The AI never reads the same sentence twice any new skill developed should indicate ability with generalised learning.
-Understanding human language at the atomic letter of uses letters and numbers instead of words increases the chance of error and makes it easier to detect statistically significant behaviour.
-A human would probably struggle with this capability guessing the next word might be easier but the next letter human beings would also struggle. Though any capability would line up with this on a really good capability would largely look like what we think human consciousness might look.
-The book I chose includes page numbers, grammar but also a lot of errors and noise. Page changes etc.
-It ought to resemble human language development (Ok I am not certain about this but it makes sense). A child development begins with sounding out words on the page and building phonemes then arranging the phonemes into words then the words into sentences. It makes sense that this would be how any machine ought to develop. Also this test that I have proposed should work as it scales up.
A test like this ought to be valuable
-It is hard if AI can manage this it could manage anything.
-Though any capability would line up with this on a really good capability would largely look like what we think human conscious might look like in that the AI would be simulating and guessing the next value based on a rich mental stimulation and the error between that imagination and reality would be the force for personal change. This creates an interesting model of how to imagine human thinking.
-It is not algorithmic specific. We could compare different approaches to generalised intelligence and adopt best practices.
-If keep same book as a measure then all tests done on same book ought to be comparable. Anyone want a tournament to build Artificial Conscious?
-I can run a genetic algorithm to try and bootstrap this intelligence. May rename this article to proposition to build Skynet on my laptop...
Conclusion
I think this is a stringent test for generalised intelligence and something and what to lead to this is analysing and testing I found my current AI didn't perform very well when calculating something like an error. Explained below why that was. It possibly would be ok to just use an entropy calculation but this would incentivise the AI to make matches but not the prediction of whole words, it would also not be weighted to spontaneous learning of rare words in the text well, it could also not be scaled up to sentences. It might be that I, in the end, fall back on information theory but I think that method of calculation is overly focused on the value of fidelity of transmission and ignores that certain words carry more information within the functioning of language itself.
So what are your thoughts does this seem like a fair test? Would it help uncover AGI?
My Test Data
Admittedly I am still gathering data on this test, I
So the top is a small 2 * 2 neural network that has the blue as the representation of the book voice and the green is the AI voice. The best outcome would be if they lined up. Given that in absence of a way to calculate it takes the average value around 0.51 as an output which minimises the error.
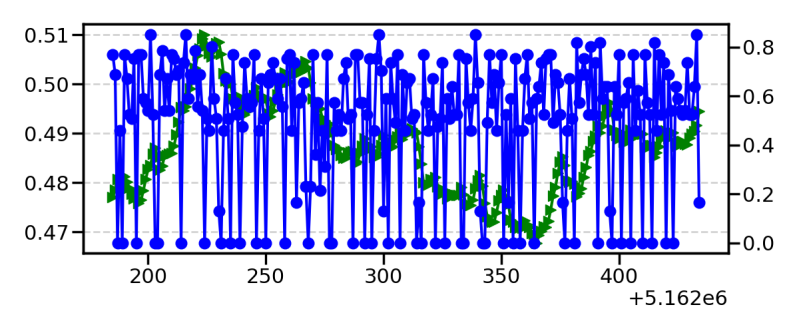
This is a 33 by 33 neural network notice it become spikier and you will take my word on this but as I flip through the 33 you can see at least a tendency for the dots to be moving in the right direction very minutely. Though I suspect I will run out of memory before I manage the test. Though I note the AI doesn't shift its voice very quickly at any point and this seems to be an element caused by how I am trying to give it memory by using a wave.
You can see that the disparity between the measurement 0-0.8 is better than 0.47 and 0.51 of the previous. Therefore the second voice is both spikier and looks more responsive but it is also stretching out over time to fit the full scale. You will note that given the size
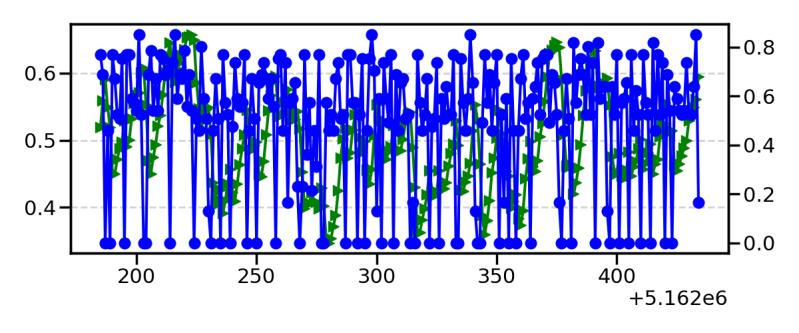
The reason I had to create this measure and think through what I was searching for when running this Ai can be seen in these two plots. You can see that if you said both were a voice then the bottom would be considered the closest while if we were to calculate the error between green and blue we would select the weaker AI. Therefore I ended up creating this measure as an analytical method to see where we can detect these c=improvements.
What are your thoughts? I am currently running a heavily adapted neural network and just increasing its size and running this test to see if the size is the biggest issue. I do have an issue with vanishing gradient and I think I have fixed that and the fact that 33 * 33 network I think that I probably got that but I may need to see what else can be done. I then tried running it and seeing if size changed the performance across the first 3 pages. The below is the first time I saw rapid learning and it's a 420 * 420 network who knows if that continues because I can't remember if it took 1 or 2 weeks to run just that 3 pages... I am gonna run out of memory and I probably need this test to see if I can find an improvement in performance other than just building a bigger network.
Add comment
Comments