"An algorithm must be seen to be believed." — Donald Knuth
I have been working with a genetic algorithm and throwing every idea against the wall to improve a neural network for stock trading. This is available on this blog under name" Please Try to remember" parts 1 and 2. One activation function that was interesting in that it performed 5 times better at the task than a regular sigmoid function.
I have reached out to a few people for advice if can patent though I am fairly certain at this point you can't in the UK and if you managed it you would find it costly to do and enforce. I am also somewhat concerned if someday someone was to discover a cornerstone technology to general intelligence and had 20 years proprietary access (20 years for terminator to learn and bootstrap itself to Super Intelligence...no thanks). So I have mixed feelings about releasing this as it falls into the category of explaining something that I haven't seen in other books on AI though I am fairly certain I could or would not want to try and stop people seeing this. So if you know somebody doing something similar would be interested in talking to them.
I think I will look into if it is something patentable (posting it in a blog may in fact not be helpful towards this) so can say patent pending though I am not hopeful over a week of trying to ask research analysts for advice and any answer I am not hugely sure will be able to.
So I thought I would put it out there as a blog. I have been testing this algorithm which demonstrated some interesting "memory" type behaviours the below was how I investigated its behaviours and as you can see demonstration how and by which methods it has "memory". I am currently playing with this for something like GPT and running the tests of a scaled up version as discussed in "Hello Earth". The se tests have been interesting but any practical use has remained elusive and might not be suitable.
Memory
The problem was that I had a inclining that the simplest way to create "memory" (whatever that might mean in machine learning) would be reliant on something like a artificial synapse as the idea that a neurone would affect a retained value in memory and wouldn't have this as a input.
The one that I had tested in the genetic algorithm was something that I could see performed better without knowing why.

So the above is a neural network trying the XOR gate test which is 2 layers of 3 neurones and a output neurone. There are two inputs (1 and 2) a trained neural network can be trained to turn on if either of these inputs are on but then switch off. I created a visualisation that you can watch here https://www.youtube.com/watch?v=CjVOanGMkvo . I personally find it easier to see why this might be useful by visualising it and why when you had a large artificial intelligence with lots of neurones why it might be beneficial for it to create these sorts of XOR circuits.
The graphs show steps and error is absolute. I had tried plotting lots of different variables from the networks before I started looking into error.
Though as you can see the above just looks like noise, so much does it look like convincing noise (specifically speech patterns) I actually tried converting it to a soundwave. It isn't pleasant to listen to listen too but it got some of the notes right...
So the reason why this neural network activation function was effective can't be related to its creation of XOR gates. I tried playing around with this. Training it longer seemed to lower the error but I also thought there was a very slight shift in pattern which seemed to shift backwards in time. Though that might be just me (I'll show some stuff later why I think does this, I agree at this time it sounds a bit outlandish).

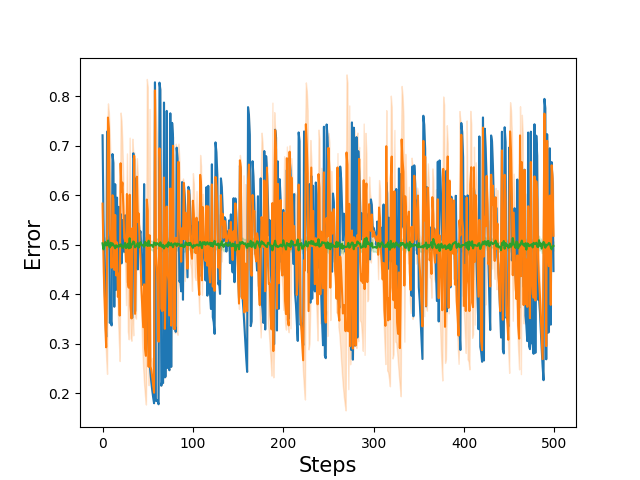
The below green line is the addition of a over trained neural network of 500 steps (exposure to random data) repeated 1000 times. Strangely it focused in on a output of 0.5 rather than learned the pattern of inputs that corresponded with a certain output. Though I already knew this was doing well on tests within my stock market AI.
I then started organising the inputs so that they where in a temporal pattern
If you can read the Python the order of inputs is organised as below.
a[np.array([1,1]),np.array([1,1]),np.array([1,1]),np.array([0,1]),np.array([0,1]),np.array([0,1]),np.array([1,0]),np.array([1,0]),np.array([1,0]),np.array([0,0]),np.array([0,0]),np.array([0,0])]
c=[0,0,0,1,1,1,1,1,1,0,0,0]
You can see first 3 values are the XOR the next 6 are positive output and last 3 both inputs are turned off.
I started to get some interesting plots. The below shows what I think is the formation of the XOR gate seen in the plot of the networks error over time. It at least looks like it has a pattern!

When training this network over time I noticed it was always out of sync when it first started a new epoch (12 doesn't neatly go into 500). This was evidence that something interesting was happening and I was thinking that the network was not fitting on the inputs but a oscillating on a time series state and the network was learning some form of wave function not a traditional mathematical function. (sounds good for analysing time series like stocks!).

Though training over time lessened the initial disruption and meant the AI values looked more like normal XOR gate. The network as you would expect from a network that output is tied to what it has previously outputted does as you expect transition between values rather than stepping between output (see video at top of the blog).

So the reason that I call it as fitting to a timeseries and oscillating was the below is a single neurone in blue and the orange is a plot of orange is what it should be. The point to think about is that while there is a input neurone and a output neurone that would allow some time series analysis there is no ability to form a XOR gate. There isn't enough neurones to form it as usually it needs at least 4 (see video). Though as you can see the oscillating neurone is able to do a fuzzy job with a single neurone as the network
It should be noted that if what mattered to this machine learning algorithm was its inputs it shouldn't be able to do this but it can do this if oscillation is purely a time frequency thing of I have learned to start moving to output 1 after X steps and down after Y.

I then tested various things where I increased size of network and trained it for longer. Both (independent and in combination) improved the network performance. Now usually with a neural network increasing its size makes it more powerful but requires it to spend more time learning and training. The below is a larger network 3 x 3 plus a output versus 1 and a output.

I noticed that the network would form a pattern but would be disrupted at the start of each 500 run. i.e. because 12 doesn't go into 500 there would be a shift in the pattern. While this did seem to improve with some training and similarly if sized up they get better at dealing with this disruption. This creates a interesting idea that even at 500 cycle time the disruption may have become just another outside pattern to be learned. That being said I reserve judgment on what is going on there.
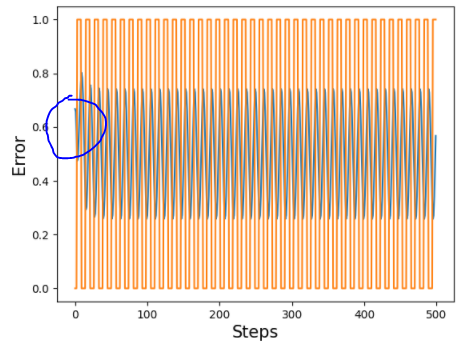
So I decided to kick it up a notch. Theoretically If the network had memory then within a larger pattern if it was a normal XOR gate but then the pattern was say a 1 when otherwise we where expecting a zero then any response would be indicative that the network was A) following a pattern in time and not related to its inputs and B) must have in some sense memory.
Python code for the new inputs.
a=[np.array([1,1]),np.array([1,1]),np.array([1,1]),np.array([1,1]),np.array([1,1]),np.array([1,1]),np.array([1,1]),np.array([0,1]),np.array([0,1]),np.array([0,1]),np.array([1,0]),np.array([1,0]),np.array([1,0]),np.array([0,0]),np.array([0,0]),np.array([0,0])]
c=[0,0,0,1,0,0,0,1,1,1,1,1,1,0,0,0]
Note c[4]==1
Then running a network you can see that there is a delay at a specific point I have circled in second photo and in third shown in 3rd photo can see the "wobble" lines up with the point where c[4] is!. Now I am sure it would be agreed that its not that perfect but even this wobble should be taken in context this AI could not do that if its learning was from inputs but only if memorising the larger time related pattern.


NOTE: please bear in mind to whatever degree it has memory is surely small though more to the point it is a demonstration that such a perturbance cannot be related to the inputs.

Conclusion
It seems likely to conclude there is some form of memorisation going on in this network and is forming its patterns from the frequency of both inputs and the time pattern. This allows the network to make its decisions related to both the current inputs and what has previously happened in the network. This design is clearly not suitable for getting a % for a classification though maybe best at making decisions and reinforcement learning where decision points require both looking for patterns in inputs but also patterns over time. I have some improvements that I am looking at.
In my head I have called this a Wave Neural Network as the activation of the neurones in the network move in waves across the network and call the neurones oscillating neurones because while the maths of averaging there values would not seem to create a liquid or oscillating feature you can see in practice the way it learns behaves much like a oscillating machine between values (as shown when using only one neurone).
I can think of different ways a neurone might "oscillate" so it might be worth testing other versions to generalise and work out what works and doesn't.
The below is a 96 row times 96 neurone using this method (way bigger than the 4 neurones needed). While it doesn't converge to nice clean XOR gate it is more interesting because I am not sure because of the vanishing gradient of a network that size how it manages that given the backwards propagation of the error probably doesn't reach that far back (I haven't tested but I have seen it drop till underflow in smaller networks). Hence why I say it is a strange algorithm the below seems like the Rembrandt version of a XOR gate. The fact it does that at all is a bit weird and seemed worth sharing and another reason I think should label it a wave network.

I also think this is probably a simple demonstration why memory probably is reliant on waves in the brain. A event of a input being 1 would be 0.5 at time step 2 and 0.25 at timestep 3. I also wonder if it is why you have ideas of conscious as waves echo and propagate slowly get to zero. With a precision of floating point down to 1e-323 any event will take 1075 timesteps for any event to disappear from the network this I would assume can be extended with additional layers or greater precision (say infinite precision say in a human brain). What's more because it decays a multi layered network could key itself to different decay points after a input has been inputted i.e. several neurones in second layer might be differently timed so all 3 turn on after a event and then equally begin a decay over time.
I have had overflow problems in larger networks doing complex things a issue that indicates a neurone is trying to "stay on" for long periods of time propagating a event at high value (as in close to 1) for a long period after the exciting influence has been removed. A neurone that multiplied the small value of 1e-323 by 1e+323 would still output a 1 at 6e-323 meaning each additional layer might add another 1070 timeframes a output can propagate in the network (with suitable error handling). This would indicate the memory can be extended over a larger network and still be utilised in convolutional logic available from neural networks meaning the final decision to do a thing or not do a thing would still be weighted.
The use case to me is likely autonomous decision making looking for diverse "events" and looking for convergence if these events have any meaning towards the target goal. These events if important could be held in memory for long time as they propagate in memory but might not cause the bot to do a thing till much later when ancillary events have also happened.
Though this also brought the problem that the AI thinking becomes a wave the output of a neurone is connected to its output yesterday and every day before that. This does seem to make it hard to train and somewhat unruly it unlike a classifier won't give a nice % of likelihood to do a thing it will develop a wave of which this wave is a rough evaluation of if should do a thing this second or not based on both inputs and memory being formed. Many use cases are not reliant on what happened yesterday or before and do not need memory and try explaining to a business person the AI did a thing because it has memory and 1075 timesteps ago a thing happened and 2 days later having thought about it and a secondary triggering event gave it the necessary secondary input it then did the thing with the thing!
This does make me think about biological brains if a AI with say the 96 layers above have a memory echoing within its processes 96 * 1070 timesteps later how long does a single thought affect our own thinking? Are people basically spending a lifetime pursuing one thought? A lovely though good night!
Add comment
Comments