Dr. Seuss. “A smile can happen in a flash, but the memory can last a lifetime.” “Hard to forget such strong memories with the best people.”
Preface
I have been working on my own neural network framework primarily for stocks and when investigating it while overall was fairly exciting because of it's manner of learning could spin out of control and spiral into some dodgy behaviours; where especially on a long successful simulation would tragically end up buying and selling out of sync with the actual pattern.
I felt this was a case of system death; whenever you create a stock market system for trading it has a limited lifespan while a successful one will last long enough to make you money it is inevitable that the market itself will change. Patterns aren't eternal and so eventual an AI will have a learned model of right and wrong that is alien to the marketplace it finds it in. This was my belief why was falling.
So I wanted to take my neural network further I wanted it to have some continuity of self. So I have been working on some artificial intelligence with what I guess would be memory. The below is to report back on what I am unsure if they are liquid artificial intelligence, momentum artificial intelligence or a different thing I have stumbled upon.
I have been using this code framework to test the maths for various implementations of neural networks which really capture my imagination.
The Test
Use a genetic algorithm to perform the neural evolution of all aspects of the design and production of the neural networks (so I don't have to). Introduce distinct non standard (many where things I wouldn't bother to do if not experimenting). Record data into a backend database of results across the different test runs.
Focus on modifications which may demonstrate or represent forms of memory within Neural Network (see hypothesis section at end or previous post).
Admission and Clarification
This is the second time I have made this test. I completed the first step and had a sleight wobble of paranoia and checked the code a couple of times, and convinced myself would need to restart and change a whole load of values. Over a set of tests, checks and balances I largely changed the algorithm and then slowly over a Saturday changed it all back to the way that it originally was...Sigh...
Therefore I lost a week but at least I am more sure of my data. Likewise the algorithm and versions may have changed in subtle ways from discussed previously. I console myself in thinking past Joe was one smart cookie.
I also changed it so the only thing that counts as "profits" is money in the bank. If in a test the network ended a session with a held stock they just get their money refunded therefore there are plenty of good or successful tests that will return a 0 or otherwise report lower values, also some stocks that are great investments will be devalued by the genetic algorithm because they are amazing long term investments and the AI is being scored on trading.
The choice to focus on this makes sure the tests are fair as otherwise you can end up with a network that gets lucky has amazon stock to trade on and actually isn't very effective but will buy and hold a stock and be rewarded thereby being propagated over multiple generations without improvements.
Also this means that if I say X network or change to algorithm gives Y dollar value you can at least infer that it wasn't because the change "broke" the AI and set it to buy and hold till the end of time...
In short I can say that the tests where fair.
I had other tests to continue with but decided to get these ones out of the way and more formally do a write up as it helps me understand my own thoughts. Though a few things I will reference I had done in previous tests that i deleted for above reasons and haven't had time to rerun the test and or myself may not choose to as for myself I have the results already.
There is a problem here because it can take several hours to run 1 test to get the 700 sample sizes usually because I can only run in the background and likewise all networks are only lightly trained for 1-3 passes through the data in a random start and end date with random buy in and this means conversely many networks are simply not trained and are inefficient or defective. This does skew numbers towards zero but is useful as no network can become over trained and I am not sure doing so really works.
Further to this as a AI if holds a stock to the end of the simulation may actually have made a fat profit (although not yet realised) and maybe the highest performing. So I am not entirely sure if the one and I am done approach isn't a issue with how score the test.
From what I have viewed so far either the AI catches a break gets the game it is playing (for lack of a better term "groks" it0 and starts responding or doesn't. You can train it a few time and either because the network setup doesn't support it action in current enviroment or something else it just fails. I might likely comment these non performance networks tend to disappear as the genetic algorithm starts to optimise the design and show up less. Likewise the networks that seem to benefit from the most training and evolved multiple runs where the version 77 which was the cycle version which discuss later.
The contenders
So I had created 7 different modifications of my MTEM program to run the tests (previous version I had 14 so this is mostly just highlight) on making various limited changes to see if can find improvements. I had focused on changes which focused on the theme of creating memory in the AI and had interpreted this broadly so that anything that created states or values that existed in between the runs would function as a form of memory.
Version 74: My standard MTEM framework without any changes.
80: A neurones final output was the previous output + new output divided by 2 (i.e. it was sort of averaged). This meant the networks output was connected with previous outputs. There was for me more specific reasons as by tying the output could allow spikes in activation but they would need to be learned and reinforced otherwise I would expect a much smoother output than 74. Note: 75 was meant to be this but an error contaminated the data.
Version 76: same as version 80 but the addition of past values and current value and dividing by two happen before the activation function transformation is applied. The sigmoid or logistic function is described here Sigmoid function - Wikipedia. This matters as you can see below the sigmoid activation function takes a value between -6 to 6 and squashes it to a output of 0-1 (see below). Unlike version 80 where the sum is always a positive value in the artificial synapse the synapse can hold a negative value of which can then have the activation function applied.
I then found a bug and corrected it in version 81.

Version 77: hard coded to create the cycle between the different parts of a MTEM. This was to see if this cycle was helpful for thr network.
Version 78: Sums the neurones output before the activation function is applied with no division by 2. As previously noted like version 76 the value for a sigmoid function takes a negative and positive value so it is possible for values to cancel each other out in the synapse.
Version 79: Applies no activation function to the output it is only the sum of previous output and new output. If this version works it will demonstrate part of my hypothesis about memory.
Version 81: receives all the other neural networks in the MTEM (see above explanation) but not its own previous output.
Version 82: I made a mistake on this. It was meant to sum the final output after the activation function -0.5 after every time step. Instead it applied 2 previous
Note: I tried to do a no activation function and timestep to show the reason non-linearity must be a requirement but it became very obvious it just wasn't working at all.
Graphs
I screwed up amount of labels. The versions from right to left version 75 version 74 , version 77, version 79, version 76, version 80,, version 78, version 81.
There is more succinct clean data below in written form. (in data section).
The below graph shows box and whisker distribution the best performing was Version 80 was the AI with memory using halfway between the last timestep output and current output. In previous steps it had performed well and superior but not quite this superior. Interestingly the broken version 75 which was broken variant of version 80 still outperformed the baseline.
Note the outlier version 80 network making 1k from one single stock! That feels unlikely to be simply a flue if it performs so well compared to others.
It is 79, 76, and 80 which related to my hypothesis about memory. Though you can see it was version 77 related to cycles in a neural network.
Though I will return to that shortly.

So ignoring profits but looking at accurate trades it is the opposite. The non-memory networks traded more often but this didn't result in more profits.
Version 77 was coded purposefully to hard codes so time cycles appeared in the data passing information backwards and forward (thereby data about previous actions was propagated forward in time). I am therefore tempted to spend some more further time picking apart this idea as while initially you would conclude less money means no good in a sense it is doing what it was intended for trading more regularly and more safely than the standard version (it just so happens the proportion of trades where it gets it wrong cost more).
Solutions I might try to look further into this (and some started on): -expand genetic algorithm to allow for more cyclic connections and run test where has evolved as standard or not.
-Combine with other versions see if momentum and cycles does something special.
-Reread my genetic algorithm I spotted a few things that I think may not be bugs but may not help the genetic algorithm optimise the designs.
-Create tests to estimate if connections relates to a cycle or feedback loop in network or purely informational. Look if either or causes improvements.
Notes: previously had done more extensive tests with this idea and all outperformed the baseline and one reason I want to revisit this idea is that in previous test it performed slightly better in profits but showed the same high number of trades. I also forced connections with a neural network and itself and others and found that getting data from other networks was more helpful than a pure cycle with your past self.
I also noted that version 77 being more accurate would find more training beneficial (the number of epochs trained is controlled by genetic algorithm) though scoring considers all networks. The genetic algorithm controls how many training exposures a AI gets before their final test of which only the final test is scored for purpose of propagating versions within the genetic algorithm; though the below considers all networks as previously been of the opinion of the one and we are done training method (as discussed above). Therefore there feels reason to revisit it as..
A) if the AI was doing more training it is exploring the problem better.
B) With more training cycles a greater proportion of the test versions in below would be earlier models trialling bad ideas.
C) I really like this idea...I would love to find evidence it works....
Pure data to illustrate
version 75 averaged 2.431464174454829 with sample size of 1284, version 74 averaged 8.718213058419243 with sample size of 873, version 77 averaged 31.383858267716537 with sample size of 508, version 79 averaged 0.8687943262411347 with sample size of 846, version 76 averaged 0.6962719298245614 with sample size of 1824, version 80 averaged 0.9713178294573643 with sample size of 1290, version 78 averaged 0.5539083557951483 with sample size of 742, version 81 averaged 19.08909574468085 with sample size of 752,

Graph to show biggest win. Note a lot of the large negative values is due to networks that really made only one trade and it was terrible... This is another reason for my we train you once (well ok a bit more) and then we are done because I am of the mindset if the network gets a bad setup and bad inputs of negative feedback they might then be screwed up and not break out into more productive patterns of trading behaviours.
I hadn't realised how crazy that sounded till i started blogging about it. I might start overtraining a network as a test and see the results... I really ought to get a wish list of tests to complete...

The below shows average win for a given network. Same again the negative values are the unfortunate AI.

The below show biggest win in a single transaction. The fact that there are outliers losing average negative values like negative values like -250 is explained by the fact that some networks during initial training.

The below shows the average time to trade. I note that the "momentum" memory group version 79, 76, and 80 etc do on average hold there position but outliers show they are willing to wait. That being said the scale is in 1000's day held and the below average data shows average around a year of waiting.
Though if get to bottom there is an explanation why that might be skewed to higher hold times. Though i think the central tendency would be accurate.

The highest held time follows the above pattern follows when plotting the highest hold time and is the reason I fee the central tendency holds.

You can see it is hard to get a opinion about trades and accuracy from graphs alone as outliers are quite extreme this skews the graph scales; and so can't really see much more with the box and whisker graphs. Accuracy represents number of trades where money was made.
You can see the below is about number of days along the left hand side and profits along bottom that length of the simulation was not a big deal in whether a network worked and started making money. You can see that regardless the majority of networks didn't trade at all and more exposure didn't cause the process to click afterwards (this being said I have discussed I am mass producing these networks and running the tests).
There are two groups that a test that produces zero accuracy can fall into one where they didn't act in a test at all and other where only action was to buy but have yet to sell. I am concerned that a well trained network may increasingly fall into the group of bought at some point and maximised its time to hold to catch as much value increase over time.
The comparison with the above graph maybe a indication of this as the trend is a greater as both graphs show a darkening around 5000 days meaning when some of these AI where in it for the long-term they where in it for the very long-term and where just holding there stock (maybe after buying at a recognised optimal buy in).
Normal reinforcement AI look to maximise some future payoff and avoid loses in a way analogous to pleasure and pain. A reason I theorise my train once and done strategy pops up is either a AI gets into a wobble between buy and sell learning more how to trade or it finds buying in once and not selling eliminates pain or risk of pain of failing.
In a poetic way if losing is analogous to pain then a AI may validly limit pain by either not playing or playing in a way that eliminates the action of selling which comes with a risk of pain. It is only the AI that counterintuitively makes a few mistakes and discovers a long-term trading process that become viable profitable traders.
There are solutions to this I am reading a book on reinforcement learning that talks about k armed bandit problem and exploration versus exploitation and greedy versus non greedy algorithms and the trick is to coax the machine into making random mistakes that it will then have to figure its way out of. Another one for the list of future tests...
There might be something inspirational to the AI struggle that #growth_isn't_safe or #no_pain_no_game. Maybe I should put something on a T-shirt and sell it on a website... I guess a very disappointing point to think on is how much computational time I have wasted on networks that didn't converge at all. I have focused on headline figures. Though the more I analysed the trading statistically the more I am convinced the AI are optimally as I have seriously considered the inputs and rewards the AI should receive as if it was a real trader; furthermore a lot of tests I did later reinforced that I think I got it right.
The picture below is the output i get highlighted is the average of all MTEMs performance in a generation and then it prints the artificial genetic code for the winner (No I wont be explaining how to read the genetic code...). I have just assumed as average profits in MTEM where increasing the AI where naturally getting better but it leads to a interesting concept that according to this a lot of these networks are either not doing anything or buying in and keeping; though there data maybe being shared laterally.

Therefore while might be disappointing it might be the AI converge on the solution of buy and wait for now and that seems a problem that these tests show I have to fix. It also brings in another concern in that does these "memory" AI work better because being more "wobbly" they make more mistakes. Having made more mistakes they learn more and having learned more they start doing more stuff.
There appears reasons to look at implementing some ideas from the K armed bandit algorithm at least during training if not in test to shake up I guess I will call them lazy AI. Whether that is actually useful or that some stocks are just not suitable to trade on, or what remains a mystery.

The data
profits: As in total money made on average for a given AI network with a stock chosen by the genetic algorithm and the network design built by the genetic algorithm.
version 75 averaged 46.03796144003116 with sample size of 1284, version 74 averaged 31.421024294387216 with sample size of 873, version 77 averaged 12.95849636811024 with sample size of 508, version 79 averaged 40.55188816193856 with sample size of 846, version 76 averaged 83.85028184429827 with sample size of 1824, version 80 averaged 153.3195789581396 with sample size of 1290, version 78 averaged 44.70528622641506 with sample size of 742, version 81 averaged 50.15585977792555 with sample size of 752,
Note values are highly skewed by networks produced that are non functional.
biggest win: The average biggest win for a network. Note as can see in graphs below outliers sometimes regularly performed many times
version 75 averaged 2.5422518177570086 with sample size of 1284, version 74 averaged 1.2799687731958762 with sample size of 873, version 77 averaged 2.5125312007874006 with sample size of 508, version 79 averaged 1.7642949929078013 with sample size of 846, version 76 averaged 0.9131283114035077 with sample size of 1824, version 80 averaged 1.9423907217054261 with sample size of 1290, version 78 averaged 0.8172940444743932 with sample size of 742, version 81 averaged 4.716006117021277 with sample size of 752,
biggest lost: Average lowest value lost
version 75 averaged -1.5716749696261683 with sample size of 1284, version 74 averaged -0.2548563699885455 with sample size of 873, version 77 averaged -1.956563779527559 with sample size of 508, version 79 averaged -1.7282549905437352 with sample size of 846, version 76 averaged -1.84910072368421 with sample size of 1824, version 80 averaged -0.7817035728682175 with sample size of 1290, version 78 averaged 0.5438162816711588 with sample size of 742, version 81 averaged -1.6868304601063835 with sample size of 752,
average wins: Average money made or lost on a trade.
version 75 averaged 0.4150881216538088 with sample size of 1284, version 74 averaged 0.5180512441381186 with sample size of 873, version 77 averaged 0.4799660450176389 with sample size of 508, version 79 averaged 0.12315855565405855 with sample size of 846, version 76 averaged -0.4262273816703216 with sample size of 1824, version 80 averaged 0.6179089715322433 with sample size of 1290, version 78 averaged 0.6807402259658577 with sample size of 742, version 81 averaged 1.305522884329363 with sample size of 752,
accuracy: Number (on average) of successful trades or state changes where the network mad3e money.
version 75 averaged 2.431464174454829 with sample size of 1284, version 74 averaged 8.718213058419243 with sample size of 873, version 77 averaged 31.383858267716537 with sample size of 508, version 79 averaged 0.8687943262411347 with sample size of 846, version 76 averaged 0.6962719298245614 with sample size of 1824, version 80 averaged 0.9713178294573643 with sample size of 1290, version 78 averaged 0.5539083557951483 with sample size of 742, version 81 averaged 19.08909574468085 with sample size of 752,
shorts: A short is defined for
version 75 averaged 0.9073208722741433 with sample size of 1284, version 74 averaged 3.4146620847651774 with sample size of 873, version 77 averaged 12.625984251968504 with sample size of 508, version 79 averaged 0.2777777777777778 with sample size of 846, version 76 averaged 0.17817982456140352 with sample size of 1824, version 80 averaged 0.3271317829457364 with sample size of 1290, version 78 averaged 0.09029649595687332 with sample size of 742, version 81 averaged 7.5438829787234045 with sample size of 752,
average held: Average time a prototype held a position i.e. bought or out of the market. Measured in days.
version 75 averaged 498.5821850917918 with sample size of 1284, version 74 averaged 770.7053414766192 with sample size of 873, version 77 averaged 548.3552086332858 with sample size of 508, version 79 averaged 398.2136524822695 with sample size of 846, version 76 averaged 306.47210558565547 with sample size of 1824, version 80 averaged 312.7202519032856 with sample size of 1290, version 78 averaged 897.8177223719673 with sample size of 742, version 81 averaged 388.2033037377512 with sample size of 752,
shortest held: Average shortest point held. Shows that
version 75 averaged 265.6339563862928 with sample size of 1284, version 74 averaged 434.5578465063001 with sample size of 873, version 77 averaged 298.9685039370079 with sample size of 508, version 79 averaged 226.07801418439718 with sample size of 846, version 76 averaged 172.68475877192984 with sample size of 1824, version 80 averaged 175.39922480620154 with sample size of 1290, version 78 averaged 577.6522911051213 with sample size of 742, version 81 averaged 207.09441489361703 with sample size of 752,
longest held
version 75 averaged 828.5560747663551 with sample size of 1284, version 74 averaged 1204.4616265750287 with sample size of 873, version 77 averaged 980.2480314960629 with sample size of 508, version 79 averaged 606.0591016548464 with sample size of 846, version 76 averaged 461.4270833333333 with sample size of 1824, version 80 averaged 490.7077519379845 with sample size of 1290, version 78 averaged 1242.2911051212939 with sample size of 742, version 81 averaged 676.9242021276596 with sample size of 752,
traded: Number of moves
version 75 averaged 2.95404984423676 with sample size of 1284, version 74 averaged 10.396334478808706 with sample size of 873, version 77 averaged 37.40157480314961 with sample size of 508, version 79 averaged 1.070921985815603 with sample size of 846, version 76 averaged 0.8711622807017544 with sample size of 1824, version 80 averaged 1.2108527131782947 with sample size of 1290, version 78 averaged 0.6347708894878706 with sample size of 742, version 81 averaged 23.538563829787233 with sample size of 752,
profitable sales: Opposites of shorts bought low sold high.
version 75 averaged 1.5241433021806854 with sample size of 1284, version 74 averaged 5.303550973654066 with sample size of 873, version 77 averaged 18.757874015748033 with sample size of 508, version 79 averaged 0.5910165484633569 with sample size of 846, version 76 averaged 0.5180921052631579 with sample size of 1824, version 80 averaged 0.6441860465116279 with sample size of 1290, version 78 averaged 0.4636118598382749 with sample size of 742, version 81 averaged 11.545212765957446 with sample size of 752,
Hypotheses
So the initial Hypothesis was that a Neural network could be improved to handle stock trades using something alike memory and the initial hypothesis can be explained in Part 1 on this website. I have found a couple of different versions and had started with 4 hypothesis. All these hypotheses focus on how an Neural Network might have some form
Previously I wrote about this Hypothesis in the sense of biological analogues that I wanted something that worked like synapses in the brain (or at least my flawed understanding). The idea being that rather than providing a output a given neurone would modify the output value in the synapse rather than a straight output.
Though I'm aware that is something closer to magical thinking and In reality I am not especially able to test something that big in one go.
Hypothesis 1: A neural network could be improved via addition of momentum, liquid or a addition of a memory that could be construed as behaving in the manner of a artificial synapse where the neurone could add or subtract from the value in the synapse and that be the neurones output rather than the output be the output.
Null Hypothesis 1: it might not or might just be a trick related to buying and holding a stock may be enough to outperform a neural network that actually attempts to play the game as intended. The reason is values tend to rise with inflation therefore buying and holding for long periods creates a minimum standard of performance which is better than trading badly which risks the principle of money.
In principle I am happy to not control or explore this it might be easier to discover that the best approach was to not have a neural network. Though I have tracked a bunch of secondary data point's such as number of trades, accurate trades etc to provide some insights if it was just buying and holding a stock,
Also t note in k- armed bandits often create explorative methods by introducing mistakes to explore alternatives in a random way. It maybe that the networks described here are more "wobbly" (not a technical term) and making mistakes allows them to explore the problem space better. This is opposed to the idea that a AI with the above traits is better due to "memory".
What it isn't: A neurone in this test doesn't know it's values in its "synapse" it just modifies it. I try to test if it is better to recycle signals and moved away from that idea.
Conclusion
Clearly the conclusion is that these types of AI worked better at trading stocks on average and they appear to do so not by increasing trading frequency but avoiding the repeat buy and selling errors in baseline version reported in last post.
This makes me hopeful that it isn't the wobble described above but something more like memory because the tests weren't showing the spinning out of control behaviour related to the standard version 74 (this is the point where i wished i described and named the phenonium).
Hypothesis 2: Memory might arise due to cycles in the network an AI which in full or in part receives its outputs as a input might represent a form of memory as a neural network might possess a cycle of inputs and outputs that might serve memory. My idea here is that signals passing backwards and forwards between a network both feels as something that resembles one way which our brains with a left hand and right side brain functions. Also in a slightly mystical manner I can imagine impulses and thoughts cycling through the brain.
My idea here is a network by fluctuating its output might pass a message to other networks which will then be passed back to it on the second step. Doing so might be the equivalent of sending itself messages in thee future. I'm not sure the method here but I could imagine the neural network receiving its own previous input and might converge on yesterdays output carry a lot of information folded into one input (hey it can't hurt to try).
Null Hypothesis 2: I have seen anecdotal evidence that the MTEM links together stocks habitually and in many cases this is cyclic. I wanted to explore the specific impact this has and is it good as a rule to start joining up connections in a ring. In some way's I don't believe I will be able to prove this true or false I only think I might seek to get a induction if the signals shared between the networks provide information or is it cycling outputs back and forth might be a method of a network sending messages to itself in the future.
Conclusion: I don't think I can accept this hypothesis but you can see that the neural network 77 traded more frequently and more accurately, and also trained more. Though that didn't translate into more money. So it isn't a hypothesis I am keen to throw away
Hypothesis 3: Memory once established and at minimum satisfies hypothesis 1 might itself satisfy the requirement in a neural network for a activation function. A activation function make a neural networks output non linear. This is important as regardless of the number of neurones it will tend to behave more like linear regression. Data scientists tend to refer to this as the "squishiness" of a function (seriously) because if the values of one layer input and its outputs to then feed into another layer where to be exact there would be no synchronisation between neurones of other layers... honestly I don't know how to explain it better without a whole article but in short a network of neurones without this squishiness and flexibility will not perform better than a single neurone.
Regardless my view was a type of memory that was like the one described in Hypothesis 1 (a network with synapses) ought to be able to fulfil the role normally attained by adding a activation function. The reason I think that was that I would assume from what I know of physics and biology I would assume that attenuation of a neurones output would take place along the synaptic path and possibly would be related to its length (though frankly I am just guessing). Therefore the attenuation and energy levels of a synapse might form its own method of taking a neurones outputs and making it non-linear as by nature a transformed sum of a output would having gone up and down over time would no longer be linearly connected to the direct neurone output.
Therefore if correct you would no longer need the activation function transformation (or maybe need a non standard one) for a neural network described by hypothesis 1. I have called this in my head a time step network as the non-linearity is achieved by summing over the time steps rather than distinct output. I find this a interesting concept I haven't read elsewhere and it would make the maths simpler for the AI.
Null Hypothesis: A momentum AI without a activation function will perform no better than linear regression. Therefore must provide a baseline of a network that acted as linear regression.
Hereafter I may use the term "the synapse" I refer to this to mean the piece of memory in the neural network that stores the retained output that intended to resemble a biological synapse and "memory" in the network. I described this better in previous post.
I added a appendix assumptions and caveats at end. Note: I am no biologist I probably will make mistakes in trying to create a computational analogy of biological structures. I apologise to any biologists in the audience if I get any terminology wrong.
All these hypothesises are probably hard to "prove" all I intend to do to gather enough data to feel comfortable that a given idea "seems" to work. Neural Networks are often opined to be black boxes in that they work but good luck with a precise explanation; and adding more layers of moving parts cant be said to help matters.
Furthermore nothing in this test will prove a AI has "memory" it just that if it doesn't function like something above I don't know what it would function as and in a problem that time and pattern of event's matter it is a good bet that a AI with memory would show improvement on this type of task.
Conclusion: Version 79 outperformed the baseline and had no activation function and while didn't outperform
Gallery
Some of the times when I plot the Neural Networks output against the networks activity also look more like what I think brain activity might look like. The below graphs all show smother lines and that GPN graph while stayed below 0 and didnt buy you can see a ebb and flow different to graphs shown on previous standard network.
Though you can see that there are also elements where showed abillity to show sudden
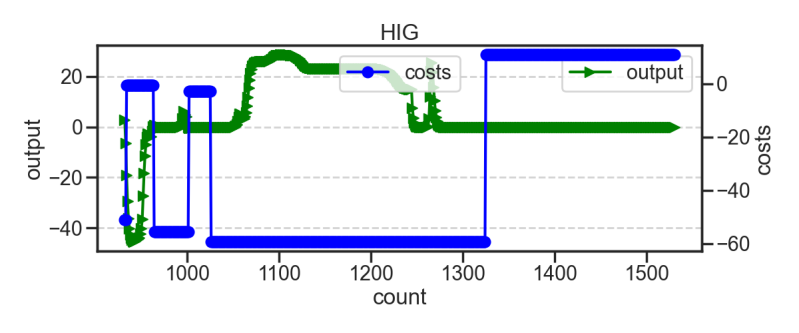
Even when it doesn't do anything it looks greater and wanders more than the previous version and in ways that looks definitely different to the previous versions.
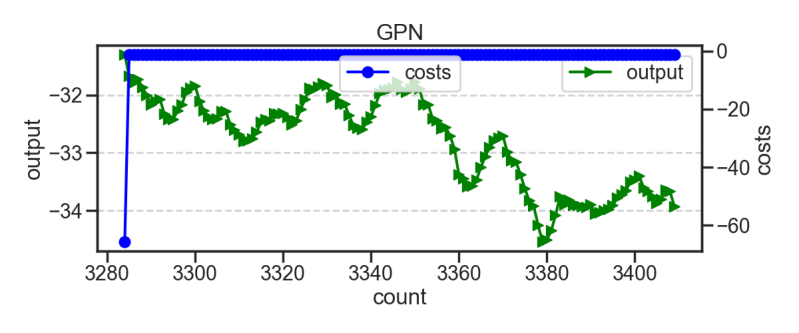
The below show's that the network doesn't struggle with spikes of activation which would seem to be the most immediate concern if tying previous and current outputs into a continuum.
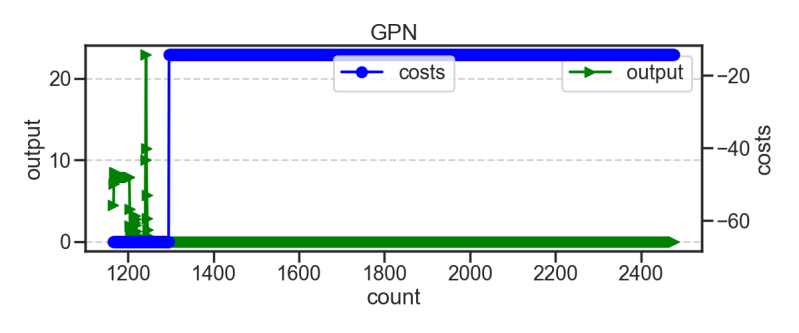
I know I am probably pushing It but doesn't this AI who sold out straight awat and then is idling look like Beta brain waves i.e. the behaviour of someone being detached and not interested?
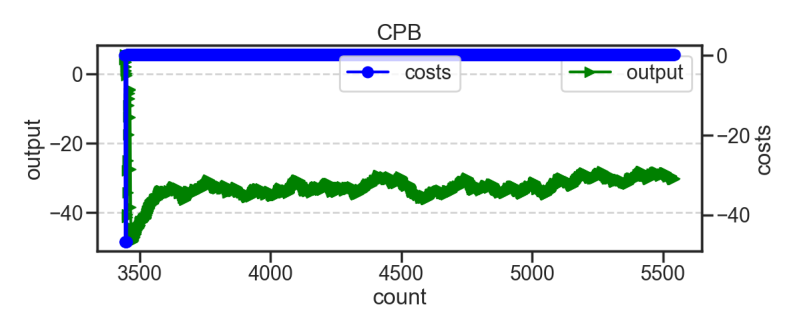
Just outcomes just in general look more biological and smoother from just a single change to the network. It is worth reflecting how small single mathematical change to whole look.
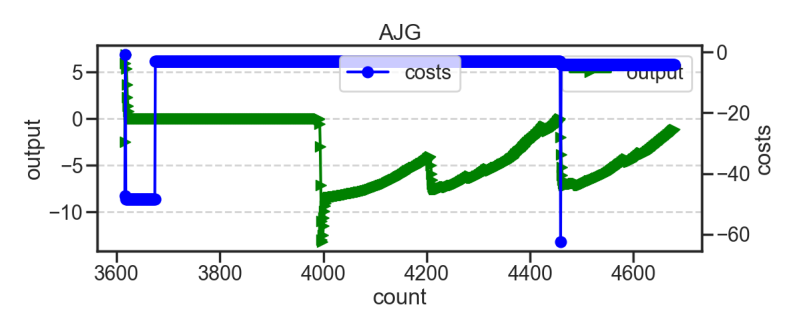
Trying to mix and match
Interestingly the attempt to add in the other idea for version 77 for the cycles between networks it disappeared and became very boxy even when added in the functions showed in version 80. The box-y-ness has left me thinking about different neurological types like dyslexia and autism in humans because it was adding only a little bit of different inputs and it completely changed the way the graphs looked and from the above data the behaviours learned by the neural networks.
This to me is fascinating it takes only a few tweaks to make it behave completely differently and it is for that reason I have relied so much on the genetic algorithm as often evolutions mistakes are more interesting than some of our best craftmanship.
A boxier version was more accurate in that did more frequent changes because the changes are more crisp and sudden they can be repeated more (or at least that's my thoughts).
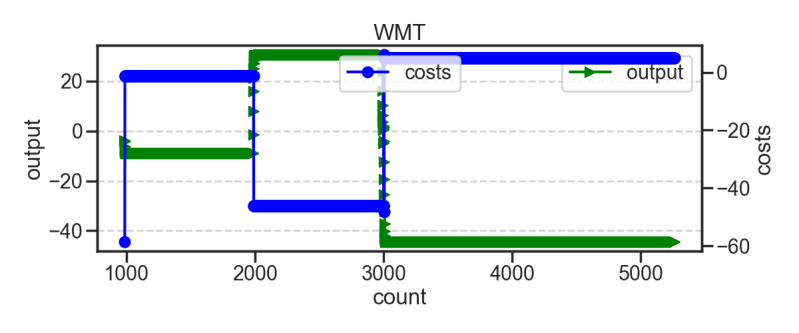
Conclusions
I feel that I have shown that there seems more than one way to build a neural network as in most cases the maths for the outputs of the neurones shown here outperform the vanilla sigmoid function markedly using some summation of the output of a neurone overtime with my thoughts this is meant to be like a artificial synapse.
So I would argue that the artificial synapses win the competition and while I cannot prove this my assumption is this has to do with memory at least in the sense that it makes more money that seems a good enough metric to argue its correctness.
As stated all the networks shown have been shallow trained 1-3 epochs of training with a random setup. Below is what happens when I start training them to maximise trading on a stock and or different critics. Though I have also accepted that that the AI function better on not simple setups.
Though I guess I have seen weird things when playing with these AI. I am not convinced they automatically outperform the human being there's plenty of instances of them getting stuck in a local minimum like many of the above graphs then something like the below appears where it buys and sells almost supernaturally in time with the market.
The network looks to maximise its trading opportunity and I doubt you could find a better trading method than the below for this circumstances the values peaked just above 0 and buy the stock often coinciding with the few market falls that take place and hold it a few days before selling it off. at a profit.
No I wasn't watching when it was made I have no idea what it was doing... but its the top 1% of the AI I've seen the code produce. I am sure this AI is not winning more than a dollar per trade but it found a mode of behaviour that does what avoids negative feedback and gets it positive feedback at the maximum frequency...maybe in people we could call that happiness...
I admitted I often feel anxious about putting my money behind these things some of my reasoning to build them was to more thoroughly understand the market. I feel that I have what is clear is regardless of the day to day speculation that happens about markets stocks appreciate nicely and this is reason to not be afraid of them.
I just ran version 87 as I am writing this waiting on the data it is vastly different to previous versions taking on ideas from previous. Likewise I have further abstracted the genetic algorithm with ideas picked up from this which should let it control whether its a more normal wiggly or boxy line as shown above.
I have other ideas on what may work and might not and want to keep trying a few over time.
I need to read up much more widely on methods used in reinforcement learning and I am interested in trying to build a genetic algorithm for making AI animals survive in a simulated environment.
I am also thinking if I can figure out the principles behind these "memory" AI or "timestep" AI (I still don't know what I would call them) I can allow the genetic algorithm to control their creation and formation.
I also think I need to do some more statistical analysis of what the genetic algorithm already does and why it does it, At the moment I know what it can do I don't know what it tends to do and how that
All this has lest me with more questions am I training them right is there better schema for reward signals because I am getting a lot of washouts from AI that didn't work. Or alternatively is this just the nature of the game that only a few position setups that function...
Though in that I have gained a lot of understandings of the markets. A lot of AI either failed a point to buy in and choose not to play, a lot bought a stock but never sold and therefore likewise played the game. Though from that a small number traded highly successfully a very high percentage in fact and as reinforcement AI is trained to avoid negative feedback and seek positive feedback you could argue all but the ones that lost money successfully did the job they where told to...
What is noteworthy is none but a very small number had insanely great runs and those that did surpassed others by several orders if magnitude.
There seems a few obvious strategies. Don't trade and do something else, trade to invest and hold for 10-20 years, wait for a decent break make some money and leave the market or become really great.
Maybe that is a cross section of actually how most people end up experiencing the market place. That sounds about right and maybe that
It is more interesting to me in that while I can show improvements in technique that improved AI performance
Assumptions and caveats
That around 700 sample size would be accurate (see previous post why this size was chosen). I do think a larger scale may have been better.
Use of the genetic algorithm was intended to allow to account for that any change to the algorithm may benefit from a different setup and the genetic algorithm would stop me having to learn how to optimise all these different algorithms.
Obviously I am assuming a improvement of memory will translate into improvement in stock trading within the randomly chosen stocks the test takes place on. If it doesn't; and or memory didn't provide an advantage then the test would be inconclusive. What I am looking for is increase that show's the momentum AI behave with some difference to a normal neural network.
The tests used my MTEM algorithm and this was a neural evolutionary algorithm that applied drop outs to the network, controlled learning rates, could create pair trading connections between different stocks. It has several direction's in which as a genetic algorithm it can improve a network's performance.
I did restart the algorithm if started with some sampling of a stock like Amazon or Google and I decided that might be unfair. That is in itself a value judgment but unlike Napoleon I prefer competency over luck.
The networks whose values where taken where sampled randomly from a run (i.e. not every network produced was counted).
The neural networks could make one buy or sell decision a day and the networks where rewarded or penalised based on the events that happened on the next day of which would be unseen. (I have recently been worried this is overly difficult on the AI but yet to fix as while harsh iI thought it was fair).
Add comment
Comments