"By far, the greatest danger of Artificial Intelligence is that people conclude too early that they understand it." — Eliezer Yudkowsky
I got all the processes working after somewhat lengthier debugging than the previous one. And what matters is loss goes down...
Introduction
I am trying to build a transformer or an AI chatbot from nothing with some vibe coding, some university papers and grit and determination. This is the tale of that bot's first working.
Error goes down! It improves end-to-end! Yipee!
It did not break the PC either. No memory leaks, it chugs away because the code I wrote has yet to be optimised. Can chug through 100s of thousands of paragraphs in a day and on my old, broken, decrepit PC.
A small dataset would still be 10,000 to 100,000 samples. I manufactured 60 just to test does error decrease period.
A more composed start
It's been a hard week; I will probably be a bit saner next week. But about mid-week, late at night, I was still debugging, discovering huge errors, most made by the AI used in vibe coding. Much of this is my debugging documents written in the midst of that, so there is a little bit of crazy energy going on. I won't lie, I had a despair moment where the vibe coding AI system pulled the rug out from me, and I had to remind myself it does not have much context, and I was pushing it a bit.
So I am going to start again and split this up. First, I will split it out and criticise my tools. I will speak about how I got a lot of the base code from AI itself and vibe coding. I will tell you why I hate it, then why I tolerate it, and ultimatley it did the job.
AI helped write another AI!
Then I will go through the implementation and naming I am using.
Criticism of vibe coding as an idea
This is a 3rd/4th C++ project, maybe a 6/7 project with AI in it. Probably 1st time with vibe coding.
When I have done something like this in the past, I always did a scrappy version in Python first, and then, when I had that right, I ported it into C++ if the build would benefit from substantial speed.
The AI does not seem to appreciate the time and cost of making objects in memory. C++ is a very elegant language with very fine control over memory, and a lot of the rules are meant to help you make and destroy things correctly and keep C++ fast because it does not delete anything under garbage collection like Python. The AI I have noticed follows the rules that people get taught about C++, but then makes and destroys big memory objects willy-nilly, often hidden by how it returns from functions.
By using vibe coding, I kind of have missed the normal draft prototype I would have done in Python, but I will definitely still need to go through and work out what the speed up will be, as this initial draft is going to be slower than it would be. Given that I definitely will need to do two drafts, there is part of me that is uncertain if I saved time.
The other thing I have noticed is that it might be assumed that generative AI would generate something like code from the Platonic realm of the forms, that is, in some sense, the best saddle point between each of the competing designs in its training data. There are a few mistakes where it built stuff that was either not the most efficient or had a bug if changed one thing, or felt like it was multiple good templates badly welded together.
I have a hypothesis that the AI dread is around this belief that AI has access to some Platonic state of real maths of things; that it is "better". I think this is wrong, it is merely faster for the "better" brain, i.e. us to offshore some of our thinking to its more rough but better recall of factual information from its weights. I think we should embrace it, but I also get the angst that it is not a perfect system, and I think much of the problem is that it is a new tool.
The impact is that AI follows all the rules but without any of the spirit of them. I am glad I purposefully did a software project and did it via Vibe coding, but on a lot of reflection, I am really uncertain if I genuinely think I would want to use it again. I think it definitely worked here, as I struggled to find many existing examples of Transformer implementations, let alone implementations of the backward pass in C++; so generating them seems like the right call, but I think there is a lesson here that vibe coding use has to be moderated. I think I would definitely use it in certain circumstances, but I think my take on it is as another great tool and not a replacement.
For example, I have ended up transcribing from the AI and not copy-pasting, and I think if I had copy-pasted, I would have had no confidence to let this run. Therefore, does this really save me time?
My take on this is that AI is a grade A research force multiplier. A lot of the AI architecture I built, I could not find examples to learn from. Most initial coding to build a minimum viable project is research, but optimisation problems, silent bugs, and technical debt would balloon if relying on it.
Issues with the vibe coding
The way it praises you all the time. It's affirming at the start, but by the end, I am paranoid it has ulterior motives. Why did you not tell me I was perfect, only good AI!
When you get more than one AI involved, it does he;p find issues, but they quickly start adding gimmicks. i.e. they add something, and it is almost certainly talked about online, but it's poorly applied there and now in what you're doing. It's like having a guy in the room randomly shout make it red cars go faster if they are red.
Ask for the same code again and again; there are small changes. I think it's inferring small editorial checks and changes, but this is unhelpful when testing, and you do a double check, and you see the same parameter slightly changed.
At one point, I was looking time and time again at a line that had d_token_embeddings_.transpose() I kept prompting the AI about this. Next time I re-asked for the code, it changed it to token_embeddings_.transpose() and radically rewritten the function.
If this were a junior developer, this would be them rewriting code behind your back to avoid a telling off! But why is the AI scared of being told off? It doesn’t even have the pain receptors for that...
I hate attention masking. Once it has added, it is hard to get it to drop, and I worried that if I asked it to, it would change the whole design.
I built assertions into each of the objects. A lot of those assertions worked with the first draft of building a transformer and were built using the AI input. When moving forward, I found myself testing the same functions again and changing them towards more robust checks.
I put this under the heading of what AI produces is easy to think falls within a “platonic ideal”, i.e. the AI will produce the centre of the Venn diagram of all coding functions and therefore is or is likely to be better than what you produce yourself. I often do not do this, but it is in many senses, lazy, producing the minimum viable solution to answer the users' questions.
In my case, the matrix in the input into layers of transformer blocks should be test y== rows and columns of x, but the multiplication process means y.rows && y.columns will now equal x.columns. Therefore, the AI set me up with code that was sufficient to answer my current query, but not in any sense ideal and then failed when further changes were made. This might seem like a very small matter, but I do not have problems like this when coding in a more planned manner.
When fixing something because of the above slight changes, there is a deja vu of whether I introduced this bug or if the AI introduced it. Therefore, there is this, I guess, seduction pushing you to blame the AI more and yourself less, which I think is dangerous. I think some of the problems I am blaming the AI for above might be due to me, but I have genuinely checked, and I have at least one instance where the changes the AI made were drastic, meaning I think it sometimes does “improve” and gaslight the user.
The AI seemed to never properly understand proper architecture. It was meant to create a function called forward, softmax, cross entropy, step, and backwards. Not only did a few times did some of these functions disappear a good few times, but things that should happen in step would move backwards. i.e. it liked zeroing d_token_embeddings_ in cross entropy calculations. This completely threw me for a while as I wondered if it knew stuff I did not. But then, how does the gradient accrue? I feel this underlines the risks of a tool that produces text from stitched-together text rather than with intent, and while I do mental somersaults over the meaning of AI’s capability with one-shot meaning, I have an abiding belief it would struggle with intent.
Masking, everything keeps telling me masking is really important because the AI cannot know what is happening in the future of the sentence. The issue isthat you do not load anything from the target IDs into the AI input. Also, using cross-entropy only lets me pick one output. In BERT-style models, you randomly assign some of the data to be blank so the AI has to infer more. But I haven't started testing different ideas like that. When using more than one, did was decide masking was a real object that needed a vector of booleans around it and then proceeded to change the whole architecture around masking. The issue is surely that I just created a
I think what it is in GPU acceleration, the blocker is passing memory about,t so setting up the full sentence and cycling through it is possibly faster to load up one sentencthanen just cycle through one matrix of memory changes, as you're not passing as much data intoGPU's VRAM. But I have elsewhere been explicitly told that it creates a bunch of saddle points in the learning, so you should randomise the order, so I struggle to get the circumstances where masking is better.
Me in a multi-way argument between the AI over this, which led to some strange code which I had to fix through testing. I have a suspicion that AI has a tendency to stitch this code together from various sources and templates, and so some aspects that make perfect sense somewhere else ended up in my architecture. Then the AI optimises around it, even though I cannot for the life of me figure out why that design choice matters here and now.
I strongly suspect that AI did not build a transformer; it built 80-95% of one and then just walked off to leave me to figure out that gap. The other deeply unsatisfying thing is I probably had just the minimum skills to fix this issue, which means the more skilled you are to fix the risks that AI create,s the more likely it would just be better to go ahead and do it yourself.
Though you can only see all that after you've written it, gone through i,t and systematically debugged, it because most of its big errors are architectural. Therefore at the beginning you feel great thinking this is helpful but all the pain is back loaded and all the joy is front loaded with the kicker is the architectural mistake it will make are only apparent at the end meaning if your using this to learn you are taking a gamble with not knowing if you will understand well enough at the end to fix the mess the AI has built.
For me, this set off rounds of refactoring and rereading code that ultimately took more time thanif I had written the code from nothing.
What’s more, there is no story or project mechanism that you can put in place to mitigate this risk.
This feels like a life lesson, no knowledge can be gained for free,e you pay in time, humiliation or the vexation of the problem. This is to say, AI vibe coding is neither programmatically nor pedagogically a sound choice. It has aspects of some of this, and it may still be of interest to some people, but it does not look to me like a sound or complete replacement.
There was a later point where I found it definitely had a size mismatch in a piece of code long ago moved on from. Asked for layer norm again and got given code that had a new line that just resized that output, so there was no issue. No subtley just outright created a new resize function after gaslighting me that the shape always should have been X.
Then, after fixing all the layers and norms, it quietly corrected the whole initial set of matrix sizes it confidently produced at the start. There is an element here where it feels that we are doing a mutual debugging of your code, plus the AI at the same time.
An example of this is I used another AI to criticise the output and provide fixes, and I had to stop it because it really ended up going into the weeds of unnecessary changes, and the AIs started asking each other questions about the rest of the project, which were irrelevant. One of the suggestions was to split the functions up into a separate softmax function, which it has eventually reverted to quietly. It's this forward function that I ended up rewriting myself and cutting out the otherAIi and only using the primary one that I started the project with.
Name of variables over time might vary. Therefore, it becomes a liability on a large enough project that it will change names 100 versions later.
There is an element that I feel this makes me thinthat, kthat, for best results, a human should sit in and listen and manage the AI agents, but if you do that, I think it does start to add value. Though then the more you lean out and let the AI automate themselves the more it feels they get carried away. All the silly problems where on the areas most redrafted by the different Ai and I have slowly been removing things as I go, not adding them. I have a suspicion that the code I am using is probably very much a copy of something that the AI I am using ingested on a website, and likely not unique, because when you start criticising it and adding to it, that feels like where the risk is that it hallucinates will grow.
There is also the matter of ego and responsibility. What has already been produced was produced under a lot of prompting, and I have already done a lot of testing. I do not think I made a mistake, but I note when using the AI its easy to blame it and use it as a crutch to build the object and then a scapegoat where it fails. This could create the worst form of design by committee.
All in all, it works, but it's not a magic bullet; it still has skills involved. The exaggeration about AI agents doing all the coding seems a flawed approach from what I can see. You need to at least read and test the code, and that traditionally takes the most time, and if you are struggling with the testing of the code, you will start reading it more and writing more of it till you stop using the AI. It's a bit catch 22 on,e like that it's good till it's not, at which point you struggle to know why you bothered. But while vibe coding worked, it will work very well for me, and I was the clever clogs solving all the problems when it didn't, it was the AI's fault and you have to learn to take responsibility for both the good and the bad if you use any v(there is a lesson in humility in all this somewhere).
What I like about vibe coding
If I tell the AI I want things changed, it tends to remember. It does feel like having a pair programmer on the same project in this regard. It does feel like, barring the criticisms above,e that you can iterate with it and work through the problems.
I genuinely feel like it's a genuine pair programming experience and gives those types of benefits.
I can treat it like I use Stack Overflow, just cycling through different examples, asking questions and trying to get advice on the problem.
When creating unit tests, it did seem to always know,w given some set of values and a rough expected val,ue which is very useful for devising unit tests and building tables of what the parameters should be.
AI is very good at one-shot learning soit'ss very good at explaining its own codede which makes it a powerful learning tool as I can flip between the code, formulas and explanation back and forth. That might sound like the ungrateful whining that my coding AI gf is not considering my feelings when writing me code, but I think a point of critical failure for vibe coding is any mismatches between the AI and user and some sort of check-in to ensure alignment would complete the pair programming simulation. A small bit that says run the code output should be X, might just join those final dots.
Above, I strongly complained about masking and stuff. There was a moment aha moment, where I learned about teacher forcing training and realised the model does need to learn the whole output sequence (up to sequence length). I had a bit of a floored moment for me. There is this thing called exposure bias. There is a mathematical level that this weirds me out because, for accuracy the generate one token at a time, but a lot of the methods try to learn long-range dependencies.
Therefore, where the element that I most strugglewith d and the AI most struggled with was where I learned the most from. There seems to be a powerful reason to consider that I should take ownership of the interaction and not assume it was because vibe coding was the issue.
I think I should be suspicious that the areas I struggled the most with and asked the most questions on are the areas that the Au might struggle most. I also think the application of masking was wrong, but broadly, everything it did had a point. Seeing less “culpable” and an “agent” anan a interactive experiential archive might be useful. It is probably the case I am just over scrutinising this section and repeated questions hint to the AI different directions it might make different changes.
I still feel suspicious, as it was going OK even at that section until I used more AI agents.
Though all of that is best used in very short sprints with expected project support, if you were already this sophisticated,d I feel that you would not need the AI.
I still strongly feel this process of vibe coding is more of a replacement for what you do to learn to code, in finding code challenges and doing them and just persevering. I can automate making those, and AI is fantastic because AI can just generate these massive code bases where the bugs are, hidden like where Wally.
Things I'd Change
I think the AI could do more to stop and suggest unit tests and just stop the user and say now please run this checklist and give me the answers so we can e confirm we are on track. I think live coding could be good for pair programming, but it needs a structure to be added.
I feel that my resistance to it would be lower if I felt it was better at stopping and making me do things that I should, including creating a learning process.
Things fixed:
Was still getting my head around all the naming systems. When the AI learns, it runs forwardcreatings and stores up error which becomes applied when calls step. Having not started running end-to-end, missed the zero grad process, which is meant to see that the gradient has been applied, and zero all the matrices, missed some matrices used for gradient in the transformer model. Without doing this would have built up errors and would have applied the sum(error) on each step. This probably would have been un- optimal and likely would not have converged, but I know from some toy tests that AI can sometimes work like this.
Had not properly initialised d_ matrices in the transformer model. What the d_ matrices should do is accumulate gradients in forward, but they were getting multiplied.
Check d_logits_.zero();
d_token_embeddings_ need to look into its use in forward.
Vibe code included the creation of a const vector of pairs. This is not allowed in C++ v17 because it makes no sense. Seriously, how did I miss that a data container I cannot add things to or change? I just typed the code out and got confused when it caused an error. I think this shows a critical issue with vibe coding, that it causes people not take responsibility.
During vibe coding, there was a fair bit of me changing things. Tokens size was being used to size the Matrix where I embeddedthe token. This seemed to be a no-brainer timer saving not to do that and return when I hit a pad token, but then the length of the token was no longer always going to be the size of the maximum size, so it could create a malformed matrix. I had to fix this. It is a small piece, but it goes to show an issue with vibe coding is that the AI makes shortcuts and those are fine in itscoded,e but they are not “platonic” or “archetypical”
Matrix Model::embed_tokens(const std::vector<int>& tokens)
{
Matrix embeds(max_seq_len_, d_model_);
Rewrote the forward function: Forward originally looked like the following.
float Model::forward(const std::vector<int>& input_ids, const std::vector<int>& target_ids,float tempreture)
{
check_sequence_length(input_ids.size());
check_sequence_length(target_ids.size());
last_input_ids_ = input_ids;
last_target_ids_ = target_ids;
//token and position embeddings
Matrix x = embed_tokens(input_ids);
//forward through transformer layers
for (int i = 0; i < num_layers_; ++i)
{
x = layers_[i].forward(x);//cycle along layers outputs
}
//final layer norm
x = final_ln_.forward(x);
//output projection
logits_ = x * token_embeddings_.transpose();
//compute loss and get gradients
d_logits_.zero();
Matrix softmax_out = logits_;
//create mask for pad tokens
//would put a mask here, but zeroes all the inputs
return sofmax(softmax_out, target_ids, tempreture);
}
Now I did a double-take when I read this and wen,,t I really sure that is missing something; not the masking that was a silly idea, the AI critic added, and I do not think I am actually ready to use it, but I sort of blinked anAIAIhe Ai had started to go off topic. But if you notice, it's missing proper cross-entropy
Silly mistakes put the smaller as greater than. This started labelling all the names in any text as .a Unk

Layer norm was quietly turning things from sequence length * d_model into d_model * d_model. This was a fault of producing a set output and not resizing.
Things added
Added step train and batch train functions. Step train takes one instance of training and applies it, and batch train does batch training, which does a whole epoch (A learning cycle for every training instance you have). Batch training is very GPU-friendly, which is why it is often the standard, but I wanted to see if it was really efficient, so building up a test to do when finished testing.
Added Assert functions to the model. These are versions of the main training functions, but are designed for heavy debugging. I realise C++ allows for debug and release environments, but I doubt I will ever release this code and the circumstances where I might would be if I built a version that was highly effective at building small models or something special, but largely I think it's a learning project.
I might add it to a list of future tests, but I would be worried about stack overflows of the floats used in the matrices.
Tried to protect against any oddities, did a common battery of unit tests for things like do the updates have any gradient in them at the end of running a backwards pass.
Honest assessment of performance
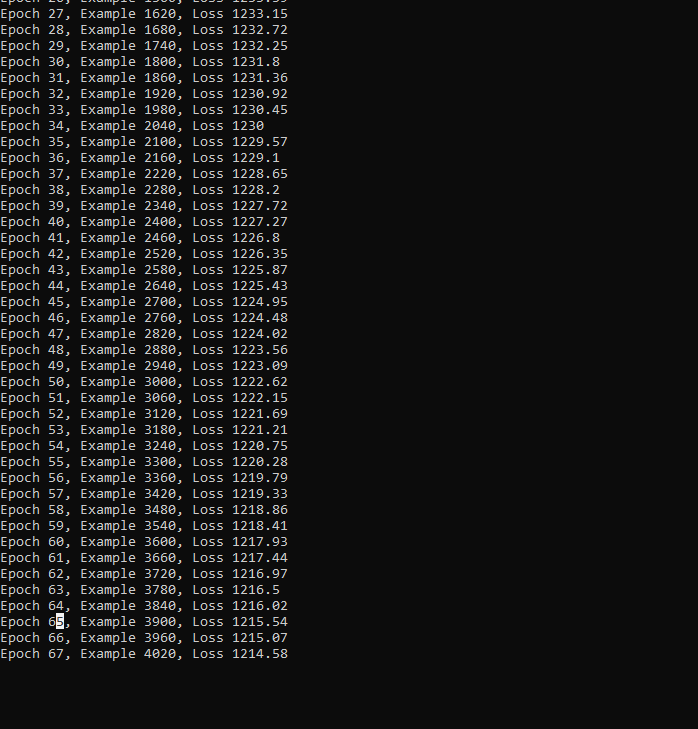
It has been a bit hard working out exactly how fast loss should fall. It definitely falls, and that means it works, but then assessing.
My data is so small that an epoch is equal to a step if was to do batch training at all.
Epoch= seen all the database
Step= one cycle and train update.
100-1000s of steps should drop 20-40%. That is a very variable range of “right”.
At Epoch 1 at 1286.4, Epoch 100 1254.96, which is 31-32, so at the low end of 1000, I would be over the 20%. Therefore, even on first draft, the AI I built was a minimally viable transformer chatbot. I used an epsilon of 1e-6, and I heard this has an effect, so I jumped up to fix that. I now have a bit of a task to run some A and B tests with the varieties.
The increase in epsilon made the loss start at 1272.53 and dropped to 1239.9 in 100 epochs, so it got down by 32.62999999999988 over 100.
I also rechecked my AI assistant for code, and magically, it has “improved” some of the forward and backwards functions, so I have a list of experiments now to do, expecting to try and nail the optimal algorithm and then start cutting off some of the fat in terms of runtime (I think there is a lot). I'd say the AI gaslights me a lot, but I feel it's hard to be mad at something that has taught me so much (and isn’t sentient or conscious (...yet,) therefore it wouldn’t accomplish anything).
Though the devil is in the detail as the vibe coding had supplied me with cross entropy, and this really only predicts how confident in the answers. A couple of readings and rereading of it, I switched to pure error, as in the total distance between all heads and a perfect prediction, rather than using cross entropy and checked it continued to get better. But as an aside, isn’t it interesting that the main AI chatbot metric that comes as standard is not about accuracy or being less wrong but being more confident? I haven’t investigated perplexity yet. Admittedly, error distance and cross entropy ended up the same, but I am just saying that if overtrained, it could give a wrong answer that was highly scored…
After fixing the error is 1224.29-1202.25=22~ in terms of total error. This is not a loss but a total gap between 100% perfect accuracy of the text and now. Multiple heads are involved doing "teacher training" (predicting text into the future, not just the next token), and it includes about 60 examples.
The area I am interested in is rapid learning small AI as I foresee not having a GPU for the future and then after maximising that performance possibly look at reusing the code base for hello world (see earlier on this blog) which would be RAM intensive (it is itself meant to be a experiment in memory intensive AI) and is unlikely to be VRAM efficient and after that I might get into GPUs.
For now, I am going to really optimise this, for example, a change in 1-e in a value lowered the error to 1197.34 from 1224.29. It feels doable to build a lightweight, efficient chatbot from all this.
List of experiments to do
I want to start optimising this in the future as a learning exercise. Vibe coding made something big and ugly. I think there are a few things to learn. I am not going to get a GPU; have you seen the cost! Plus, they kind of have their own APIs I would have to adapt to. So I would like to focus on just doing things on the small language model end as a learning exercise.
Lots of fat on the current system. Vibe coding creates and destroys a lot of Matrixes. There is a lot of speed to be gained just by stopping a lot of that
Try implementing flash attention?. I am testing on CPU-bound objects as a learning exercise. My understanding is they use a version of softmax with running sums for the max and norm. There is a 2023 paper on flash attention. I think this is mostly a GPU method, but I think there are ideas worth trying.
I think sandwiched in this want-to-do list of experiments to do things... i havent decided all of that...
List Matrix sizes used in Transformer Model
- Seq_len refers to the sequence length of the input, which sets out the maximum size of the input.
- Vocab_size: sets the maximum number of words that can be included as a vocabulary.
- d_model is the model dimension (hidden size).
- d_ff is the feed-forward dimensions
- is the number of attention heads
- dim (as in dimensions) equals d_model/num_heads
In my starting modelling
//model hyperparameters
const int max_vocab_size = 100;
const int d_model = 64;
const int num_heads = 4;
const int d_ff = 2565;
const int num_layers = 3;
const int max_seq_len = 20;
const int batch_size = 4;
const int epochs = 100;
const float learning_rate = 0.001f;
const float clip_value = 1.0f;
This should put it into the Tiny model range of 100k-500k parameters. Equivalent of DistilGPT-2. For example, GPT1 would be 10 million to 50 million parameters, only 4-16 times bigger. Bert would be 100-500 times larger, GPT-2 about 1000 times higher, and GPT-3 would be 10,000 times bigger than it.
You might be dismissive of this, but it should be OK at next character prediction, should manage basic word-level language modelling, do fair simple text classification or basic machine translation. Though you would get poor natural human text translation and very limited Q&A capability (i.e. limited as a chatbot).
This would be because an AI this small has a simplified understanding of the way the words relate to each other, but probably has an idea of meaning and probably picks out key words that trigger relations. i.e. in what we are trying, it might tie dog and cat to being a pet, but not really understand much about the semantics or all the relationships between cat, dog and pet.
It would be perfectly capable if used to take in 100 words and take a list of labels, and just spit out the labels that the work should have. Greater than 100 words it probably struggles with long-term dependencies in the language. Its size would make it good at simple pattern matching. Could be trained in login patterns. Though this is not a limit on the code, as you could stand up much bigger by changing the starting commands and the code would oblige.
Its not a lot of RAM (I really have not optimised, so this will drop again.) I could probably easily manage GPT-1 scale even on my old battered PC (without parallelisation or GPU acceleration to boot). Maybe even a bit bigger, but it would be slow (again pre optimisation I need to do a study on this).
To put it in perspective, I have Python projects that are more RAM-heavy. It's about the size of a large excel.
Parts of a whole transformer
Token, positions and embeddings
token_embeddings_ size: [max_vocab_size,d_model], Description: stores embeddings for each token in the vocabulary. Where used: used in the forward pass for token embedding, can also be used in output projection (weight tying).
d_token_embeddings_ size: [max_vocab_size,d_model], Description: gradient (think learning, modification or change) to the token embeddings that represent the words. Updated in the backwards pass and applied in the step function.
position_embeddings_, Size:[max_seq_len,d_model], Description: stores positional encodings for each position in a sequence; these are added to the token embeddings to create a composite input of the numbers representing the Word or token and a set of numbers representing their position in the text or input. Used in the forward pass to add positional information, specifically the encode function.
d_position_embeddings_, Size:[max_seq_len,d_model], Description: gradient (think learning, modification or change) to the position embeddings that represent the placement within the sentence. Updated in the backwards pass and applied in the step function.
Main Model Matrices
Logits_, size: [seq_len,vocab_size], Description: Output logits (intermediary values) that represents scores for each token at each position prior to being turned into a soft max probability distribution for the list of possible words. Computed in the forward pass and used for loss calculation.
d_logits_, size: [seq_len,vocab_size], Gradient of the loss with regards to logits. Computed in the forward pass and used in the backward pass.
x(local), size: [seq_len,d_model], Description: intermediate hidden state used at various points. Used through the forward pass but not saved as not used in the backward pass.
Transformer Block Matrices
x_,size: [seq_len,d_model], Description: saved input to block for backwards pass. Saved in forward as the input the block gets and used in backwards.
attn_out_, size: [seq_len,d_model], Description: Output of attention layer. Saved in forward as the input the block gets and used in backwards.
y_, size: [seq_len,d_model], Description: Output after first residual connection. Saved in forward, used in backwards.
z_, size: [seq_len,d_model], Description: Final output of the block. Saved in forward, used in backwards.
Multi headed attention matrices
Wq_ size: [d_model,d_model], Description: Query projection matrix. Where used: used in the attention forward pass.
dWq_ size: [d_model,d_model], Description: Gradient for query projection matrix. Used to collect the gradient (think learning) for Q.
Wk_ size: [d_model,d_model], Description: Key projection matrix. Where used: used in the attention forward pass.
dWk_ size: [d_model,d_model], Description: Gradient for key projection matrix. Used to collect the gradient (think learning) for K.
Wv_ size: [d_model,d_model], Description: Value projection matrix. Where used: used in the attention forward pass.
dWv_ size: [d_model,d_model], Description: Gradient for value projection matrix. Used to collect the gradient (think learning) for V.
Wo_ size: [d_model,d_model], Description: Output projection matrix. Where used: used in the attention forward pass.
dWo_ size: [d_model,d_model], Description: Gradient for output projection matrix. Used to collect the gradient (think learning) for the output.
Q_(local), size: [seq_len,d_model], Description: Queries for all positions. Used in attention forward pass.
K_(local), size: [seq_len,d_model], Description: Keys for all positions. Used in attention forward pass.
V_(local), size: [seq_len,d_model], Description: Values for all positions. Used in attention forward pass.
Qh_(local),size:One per num_heads*[seq_len,head_dim],Description: Queries split by head. Used in attention forward pass.
Kh_(local),size:One per num_heads*[seq_len,head_dim],Description: Keys split by head. Used in attention forward pass.
Vh_(local),size:One per num_heads*[seq_len,head_dim],Description: Values split by head. Used in attention forward pass.
Scores_(local),size:One per num_heads*[seq_len,seq_len],Description: Attention score. Used in attention forward pass.
Ah_combined_,size:[seq_len,d_model],Description: combined attention head outputs. Saved in forward, used in backwards.
d_softmax(local), Size: Num heads X [seq_len,seq_len], Description: Gradient of softmax in attention. Used in the backward pass.
d_scores, size: num_heads * [seq_len,seq_len], Description: Gradient of attention scores. Used in the attention backwards pass.
dQh, size: num_heads * [seq_len,head_dim], Description: Gradient of Q (query) attention scores. Used in the attention backwards pass.
dKh, size: num_heads * [seq_len,head_dim], Description: Gradient of K (key) attention scores. Used in the attention backwards pass.
dVh, size: num_heads * [seq_len,head_dim], Description: Gradient of V (value) attention scores. Used in the attention backwards pass.
Feed Forward Matrices
W1_, size:[d_model,d_ff],Description: First layer weight matrix. Used in feed-forward forward pass.
DW1_, size:[d_model,d_ff],Description: First layer gradient weight matrix. Used in feed forward backward pass. Updated in backwards pass and applied in the step function.
W2_, size:[d_model,d_ff],Description: First layer weight matrix. Used in feed forward forward pass.
DW2_, size:[d_model,d_ff],Description: First layer gradient weight matrix. Used in feed forward backward pass. Updated in backwards pass and applied in the step function.
B1_, size[1,d_ff],Description: First layer bias. Used in feed forward pass.
dB1_, size[1,d_ff],Description: First layer bias gradients. Used in feed backwards pass.
B2_, size[1,d_ff],Description: Second layer bias. Used in feed forward pass.
dB2_, size[1,d_ff],Description: Second layer bias gradients. Used in feed backwards pass.
H_ (local),size: [seq_len,d_ff], Description: hidden layer output. Used in used in the forward pass of feed forward system.
Layer Normalisation Matrices
gamma_, Size:[1,d_model], Scale parameters. Used in the layer norm forward pass.
dgamma_, Size:[1,d_model], Gradient to scale parameters. Used in the layer norm forward pass.
beta_, Size:[1,d_model], Scale parameters. Used in the layer norm forward pass.
dbeta_, Size:[1,d_model], Gradient to scale parameters. Used in the layer norm forward pass.
last_output_, Size:[seq_len,d_model]. Last output for the backwards pass. Saved in forward to use in backwards.
Temporary Matrices might come up
Softmax_out, Size:[seq_len,vocab_size], Description: softmax of logits for loss calculation. Used in forward for loss calculation.
dx(local), Size:Varies, Description: Gradient with respect to input to a layer. Used in backward passes.
Functions
Forward: Runs the model “forward” and “guesses” the next token.
Backwards: Runs the process in reverse and calculates, given the correct answer, what the correction that needs to be applied.
Step: Applies the gradient calculated in the backwards pass, so if the backwards pass calculates how much to learn step goes and changes the model weights.
Glossary:
Token embeddings: A word in a chatbot is represented as a set of numbers. The learning process can change these numbers during training and over time, related words get pushed together that are semantically similar.
Weight tying: Is a technique used in transformers and other ANN to reduce the number of parameters used. Instead of using softmax and cross entropy, the output vector can be treated as a word-to-vector, reusing the token embeddings to represent the output again as a vector, tying the two together (I want to try using this later). The other place it can be used is in models used in translation, they have encoders (take the sentence to translate and encode it) and decoders (create the sentence translation decoding too), but it is common to reuse parts of both in each other, so the same matrix of numbers is trained in both, and only parts are then language specific.
logits intermediary values within the maths.
Bias: a weight just added to another calculation. So to simplify the feed function a input comes in, the actual weight multiplies a value and a bias adds to it.
(local): just added if the matrix is calculated from weights and inputs, but not saved or used elsewhere (nearly always because used once to calculate output and not needed in the backwards pass for learning and therefore not stored).
Add comment
Comments