"Time is what we want most and use worst" - William Penn
This is a longstanding project of mine to build a realistic simulation of the mammalian brain at least at a simulation level. This takes the Hodgkin and Huxley simulation of a mammalian neurone and packages it in a artificial neural network.
I have been using this as a exploration tool to think about where larger AI is going and to explore if I think architecture like the transformer is capable of AGI. A lot of this is a long term study of how closely you could simulate the human brain and build towards AI.
What I have been getting is something like the below with big spikes in error up and down.
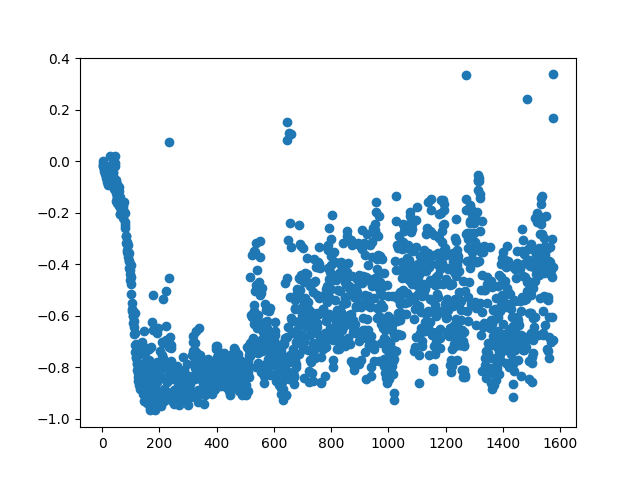
My intuition is that if you look at the silhouette of how it fires it is capable of double firing but takes a much higher force to move the second time (red step is much higher than first). Also note the second firing peak in the top blue line is smaller even though in the third graph the affect on the ion channels are the same.
Therefore unlike a normal neural network the input is not directly related to output directly and is also dependent on the timing of any input. You can note the second red firing potential is 10 times the voltage but the neurone fires at 10 volts less (40 too 30 (ish)).
There is a different theory of information that the actual information being learned by a AI the actual weight is less than the timing value. I.e. when matters vastly more than by how much and would likely mean that a neural network that can learn it would out perform the standard neural networks like the transformer. Though the above shows that using these ordinary differential equations as a activation function is not enough likely owing to this timing issue.

When doing different experiments with it I would find that the error shows short bursts of accuracy. A example below shows generally the AI is less than accurate but has these weird spurts of coherence.
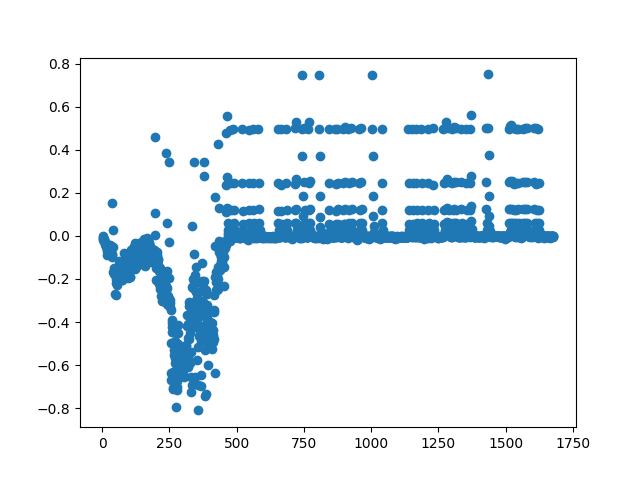
My best performing will sometimes hit 13% which is trying to recreate the reading of Dracula novel. If you look at letter frequency for English you can safely exclude that it was down to excessive use of a single letter as that would be around 12% if exclusively used E so intelligence must have been recreated in the network.
On average trial and error attempts has upped the accuracy. I am no longer using gradient descent or more specifically it would be complicated but I have been basically focusing on this sort of weird belief that the issue of linear algebra based neural networks are inherently faulty.
Criticism of the Traditional Transformer
I think this tests show something that is worth thinking about. Just taking the equations for the ordinary differential equations of human neurones and try to train them even with really careful design they still are less accurate. The assumption I have started thinking under is this that transformer is flawed in this way that you are learning the weights but not managing the timing what you would get is a neural network that learns a series of spurting flashes of AGI that it will connect A to B word to vector points in space but the end result without also learning exact timings to all firing it might manage in the above short bursts of coherence but without the wider timing functioning it would not be "thinking".
If you think we have articles like sparks of AGI then it makes sense why you would get this outcome. Its sparks could be thought to be sudden firing in spectacular ways but unable to sustain laminar flows of information and in some way our brain manages this.
[2303.12712] Sparks of Artificial General Intelligence: Early experiments with GPT-4
"thinking" might require not only learning how much to fire but also when to fire and that the SoftMax activation and attention might have worked but clearly our brain handles learning those timings in a much more sophisticated way. All of those ion channels in the above graphs are dependant on chemical concentrations in the neurone and might be changed moment to moment by our biological brain. That if that is true current AI technology might simply not work further and AGI might not materialise if timing becomes more important than the weights as a network scales.
Even if SoftMax and attention is the solution we are going to have to at some point explain how these two highly different mathematical principles produce similar results.
I think if you see in these networks where their error is spiking it suggests there are points where the network is just fragmented and not aligning up for the next learning moment. If you take that to an extreme a AI that does not respect or account for timing like our brain does would be like fragments of thought but not flowing from one thought into the next. If you built a big one maybe you would get what we have in the transformer a AI that dangerously hallucinates because that timing is lost. It seems my pet hypothesis at the moment; AI could be having thoughts yes but if the timing is off it could not pass that back to itself meaning it would tend towards hallucinations and instability; yes adding memory would help but if you pass memory back in and its like the above screenshot where firing was mistimed it would be disruptive surely. Anyway Ill save that for a Sci Fi novel or something but it convinced me this is why the Transformer model hallucinates.
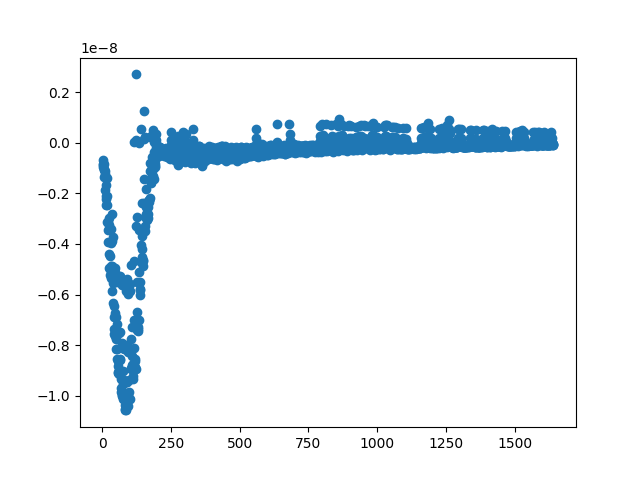
In the below graph the neural network brain simulation was carefully designed to continuously grow, it is learning from reinforcement learning hoping to be most similar to human learning. It has very low error being 1e-8 or between 0.000000001 - 0.0000000001 and had the 13% accuracy where it sometimes picked the upcoming letter. You can see that it is very lightly trained.
I think personally I think the route is to simulate the human brain more closely but I might be a rarity in that as the statistical AI is currently beating biologically plausible neural networks in implementation. Though I think this comparison shows why they might actually be highly flawed. I think SoftMax because it produces a probability distribution of distinct classes and not a timing function I feel that I suspect it just could never manage something like what the brain does. I find the constant talking up of the transformer architecture as being capable of AGI a little disquieting given how different the two appears mathematically.
Redacted Redacted Redacted
Yes you probably have inferred its not just the same as a traditional ANN at the heart of these. No I am not going to elaborate. I hope you understand A) its not accurate enough yet B) if it was I would probably go dark and start a tech company.
Started On Network Analysis
Been building up on a battery of network analysis tests. They tend to all look like this. When I have changed the network building processes they change more dramatically which makes me think how I construct them matters more. All of these networks are continually growing during testing and the below are all photos at time points in its development. I am trying to build it so the network can be grown in response to its error signals as it learns and therefore not need a data scientist.
I have had some success here but it does sound cooler to grow a AI than it is in actual application.
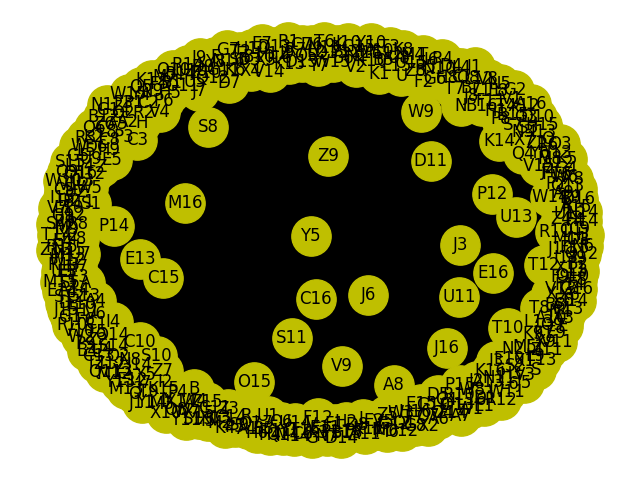
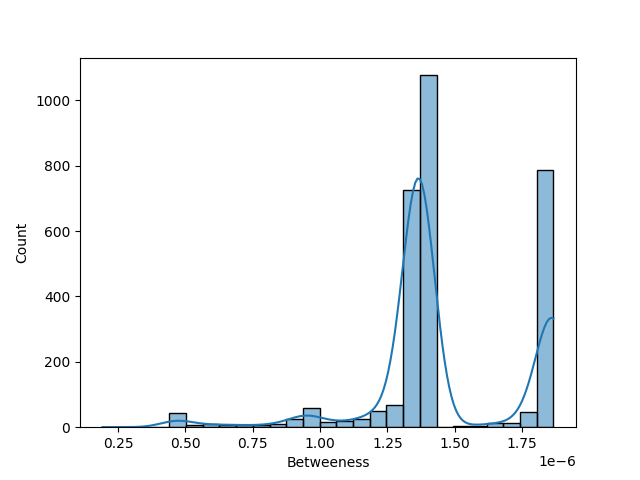
Though if I do hex graphs there is differences in the neurones locations by seeing how closely they are weighted and connected to each other shows that some of the connections are more important and central hubs exist even after short bursts of training.
Pushing this extensively gets messy so I had to figure out different ways to assess if any self architecture was happening from the neural plasticity I was attempting. The below still suggests there is a strong very connected outer ring and a central denser area in the centre of the network which has dropped some of its connections and is therefore acting as what I assume is some form of sub network within the larger brain simulation.

I used hex mapping with quite large binning to see if could say if anything was forming
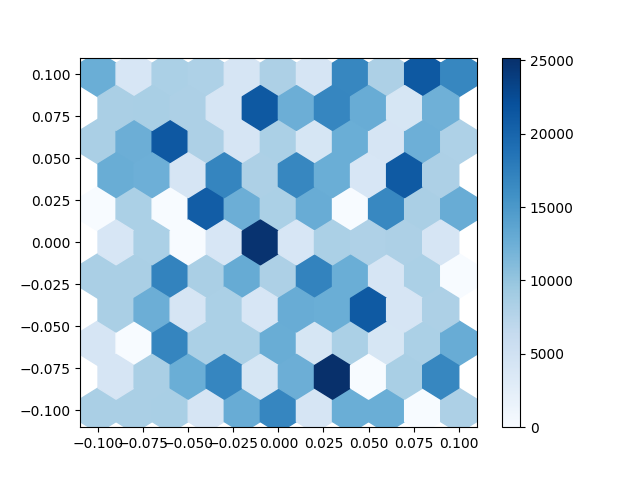
They also show a fluctuation on other tests for sub networks which they should all be identical if the neural plasticity I built was not working. This makes me think with the implementation of the neural plasticity system I put in the network is changing the shape of the network.
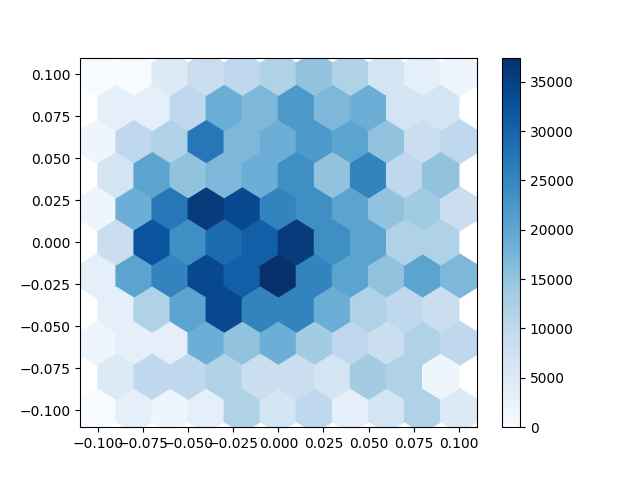
I also had some oddities like the below where the graph would indicate something like a emergent network. I still do not know precisely what causes the below to form versus the other hex map. I think it might be a artefact of me changing the algorithm that builds it and not a sign of being more efficient.
Though I am not sure if that is really doing anything but it is at least interesting; because one day potentially could pattern of neuroplasticity an AI that self builds. I mean I have 13% accuracy even though rapidly building it so I think this might be possible in the future to not have to architecture the neural networks but treat them as simulated neurones self connecting to each other in response to its training.
I also think that the timing issue should be persuasive that a gap remains between the transformer technology and the human brain which behave very differently. Even looking below it is easy to see that if you had a given neurone there currently is no process that we apply in ANN or transformers that is analogous.
I mean look at the below a group of biological neurones MUST exactly line up in time in order to fire or simply will not do it. It seems obvious to me that this timing is simply absent in current technology.

Add comment
Comments